Über epidemiologische Modellierungsmodelle und alternative Ansätze
Als Nachfolge auf das Gespräch, dass wir vor zwei Wochen in diesem Kanal geführt haben, kommen Pavel und ich erneut zusammen und gehen noch einmal etwas genauer auf die derzeit viel diskutierten Berechnungsmodelle ein, mit denen die Öffentlichkeit über die Risiken und Chancen der Coronakrise informiert wird.
Desweiteren diskutieren wir auch umfänglich die Quellenlage, die Qualität der Daten und ihrer Bereitstellung sowie die Aussagekraft auf Basis der aktuellen Datenpunkte und welche neuen Quellen und Parameter in der Zukunft hilfreich und auch notwendig sein werden.
Dabei überprüfen wir auch die eigenen Prognosen, die vor zwei Wochen angestellt haben, welche Berechnungen und Methoden in anderen Ländern zum Einsatz kommen und wie dort mit der Bedrohungslage umgegangen wird.
Zum Schluß stellen wir uns natürlich die Frage nach der nahen und fernen Zukunft. Fragen, die wir nicht immer beantworten können, aber die wir uns jetzt alle stellen und denen wir uns auch zu stellen haben.
Für diese Episode von UKW liegt auch ein vollständiges Transkript
mit Zeitmarken und Sprecheridentifikation vor.
Bitte beachten: das Transkript wurde automatisiert erzeugt und wurde nicht nachträglich gegengelesen oder korrigiert.
Dieser Prozess ist nicht sonderlich genau und das Ergebnis enthält daher mit Sicherheit eine Reihe von Fehlern.
Im Zweifel gilt immer das in der Sendung aufgezeichnete gesprochene Wort.
Formate:
HTML,
WebVTT.
Transkript
Tim Pritlove 0:00:32
Hallo herzlich willkommen zu u k w.Unsere kleine welt ausgabe nummer vierzehn in schneller folge denn es gibt ja genug zu erzählen zu berichten zu fragen und genug modelle im kopf zu halten.Und ja ich kehre im prinzip hier kurz zurück zum.Anfang dieser kleinen serie und begrüße den pavel hallo pavel.
Pavel Mayer 0:00:59
Hallo hallo tim.
Tim Pritlove 0:01:01
Ja pavel da haben wir relativ früh einen ersten vorstoß gemacht und ich hatte auch so ein bisschen den eindruck insbesondere wenn ich mir die reaktionen in den kommentaren angeschaut haben da war die welt noch nicht so richtig bereit fürunseren mentalen vorstoß gab da auf jeden fall eine menge aufregung.Was kann habt ihr das schon mal genauer angeschaut hast.
Pavel Mayer 0:01:26
Nicht aktuell aber danach ja die tage in den tagen danach.
Tim Pritlove 0:01:30
Ja und da fiel mir dann auch auf dass ich vielleicht vergessen habe ich fand es in dem moment nicht so wichtig aber vielleicht ist es an der stelle nochmal ganz wertvoll darauf hinzuweisen.Was so ein bisschen deine qualifikation betrifftjetzt ist es nicht so dass du experte in pandemien berechnung bist oder irgendwas in dieser richtung aber ich denke man kann zweisachen auf jeden fall mal festhalten also erstmal bist du seit ionen im computer bereich unterwegs und beschäftigt sich schonsehr sehr sehr lange mit software mit algorithmen mit komplexen systemen aller art ich glaube du bist auch schon seit dreißig jahren länger.Fünfunddreißig jahren da schon dabei.
Pavel Mayer 0:02:18
Ja und nicht nur dass so eine zeit lang so in den.Neunziger fang der zweitausender jahren habe ich auch eine menge forschungsprojekte mit krankenhäusern gemacht dass ich weiß ein bisschen wie es dazu geht also ich kenne sozusagen auch ein bisschen so die andere seite also ich bin da jetzt nicht ganz unbeleckt aber jaich bin halt kein epidemiologischeaber so ich weiß trotzdem ganz gut wie das immunsystem funktioniert zum beispiel habe vor ewigen zeiten mal einen netten.Beitrag darüber geschrieben es ist auch sehr sehr sehr sehr spannend so dass es wirklich ziemlich abgefahren aber egal wir es ist jetzt glaube ich nicht so das thema und ja somit gut mit zahlen undnumerica und somit analysen kenne ich mich auch ein bisschen aus also ich habe ganz gute naturwissenschaftlich mathematische grundkenntnisse so.
Tim Pritlove 0:03:11
Und der zweite aspekt der vielleicht wert ist nochmal beleuchtet zu werden ist du hast ja bis vor ein paar jahren wie lange ist das jetzt her vor zwei jahren warst du ja abgeordneter hier im abgeordnetenhaus.In berlin.Teil der der der der der wilden piraten fraktion und hast von daher auch interessante einblicke gewinnen könnenin wie so ein staat funktioniert und wie er sich vor allem auch mit gefahren beschäftigt.

Pavel Mayer 0:03:45
Also ich war in der zeit ja mitglied des wirtschaftsausschusses des ausschusses für beteiligungsmanagements.Und controlling wo ich auch da.Tun hatte unter anderem mit charite und also mit deren geschäftsberichte und geschäftspolitik da musste der mussten die vorstände dieser beiden konzerne auch jeweils immer.Einmal im jahr mindestens bericht erstatten und sich fragen stellen alsoinsofern weiß ich auch ein bisschen über die problematik im gesundheitssystem und duale krankenhausfinanzierung und.So diesen ganzen kram aussehen war ich noch mitglied im verfassungsschutz ausschuss und in der kommission wo es dann eben mehr darum ging haben wir die rechte von extremisten zu wahrenund dem verfassungsschutz ein bisschen auf die finger zu schauen insofern gab es da auch in der zeit einige situationen wo ich dann zumindest gesehen habe wieso im bereichinnere sicherheit die ganzen dinge funktioniert auch die koordination zwischen den ländern und oder auch nicht.Zwischen den ländern und realitäten zwischen bund und ländern und so also ich hatte da viele viele interessante einblicke auf jeden fall.

Tim Pritlove 0:04:57
Gut trotzdem wollen wir uns heute ein weiteres mal den zahlen zu wenden undwir sind ja da auch ursprünglich dazu über das thema eigentlich auch zusammengekommenweil du dir halt vor allem aus grundinteresse herauserstmal die modelle angeschaut hast die da jetzt gerade in der öffentlichkeit hin und hergeworfen werden mittlerweile dürfte jeder bürger irgendwas von exponentiellenzahlen entwicklungen gehört haben aber das ist es ja nicht alleine diese voraussagen über wie sich so eine pandemien denn ausbreitet und welche gefahren damit verbunden isthat ja eben auch extrem viel mit modellen zu tun und dagibt es jetzt auch nicht unbedingt das eine modell was alle benutzen und was irgendwie seit fünfzig jahren die wahrheit ist sondern das ist alles eine sehr.Fluide.Mit extrem viel abwägung einschätzungen und sonstigen faktoren versehene gesamtrechnung wo die forschung im prinzip am laufenden meter voranschreitet so wie es heute gemacht wird.Wurde es vielleicht vor zwanzig dreißig jahren nicht gemacht sprich auch die erfahrung aus alten.Partytermin oder epidemien lässt sich auch nur teilweise vor weiter nutzen beziehungsweise hat sich einfach die erkenntnis lage und die forschung nation in dem bereich verändert.
Pavel Mayer 0:06:23
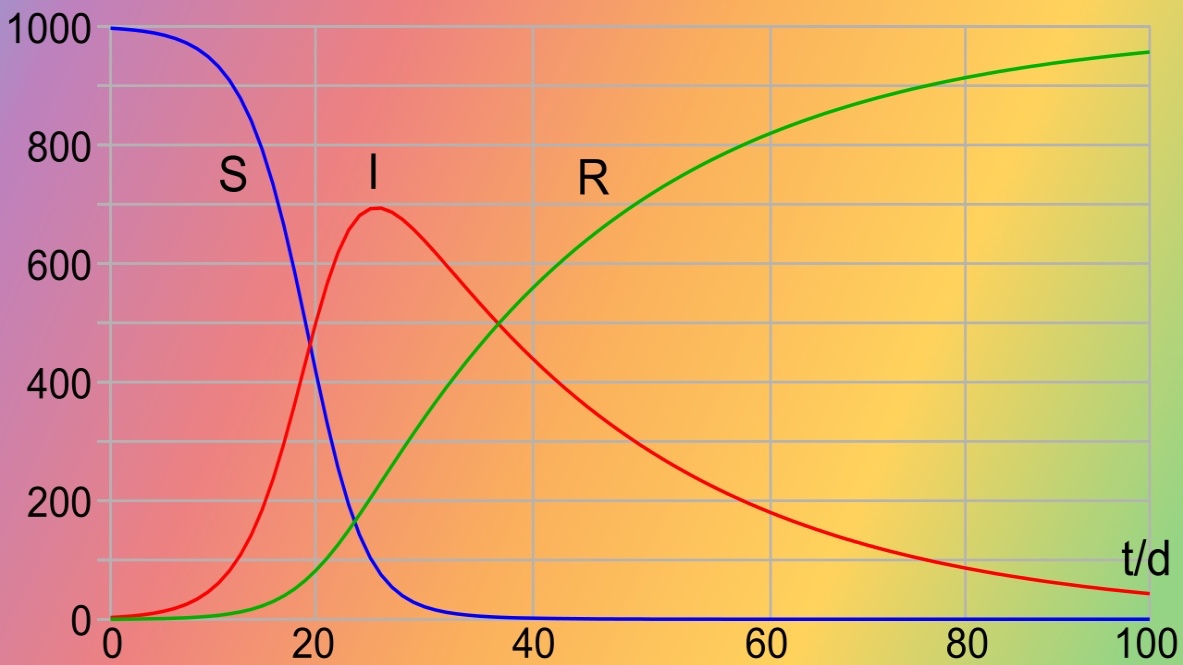
Ja natürlich hat man heutzutage viel mehr daten und deutlich bessere modelle und.Letztlich sag mal kurz zusammengefasst wie das sagen die profis machen ist die haben halt sehr.Plexi netzwerk modelle da gibt es im übrigen auch einen ganz schönen podcast zu.Vom den man vielleicht hinterher verlinken können speziell zu dem thema von den profis aber ich kann's ja mal kurz zusammenfassen wie das da so läuft und.Letztlich die modelle die am meisten verwendet werden basieren auf.Parlamenten also man definiert bestimmte gruppen von personen das sind die sogenannten modelle so ist das rezeptbibel also empfänglich führeneine ansteckung infekte gerade angesetzt und remove so also nicht mehr ansteckend war weil entweder immun gewordenoder bereits infiziert oder verstorben so das gilt alles als remove danndas ist halt ein sehr einfaches modell und da nimmt man dann ein system von differentialgleichungen was beschreibt wie viele jetzt jeweils in einem zeitschritt von dem einen compartments in das andere wandern also sprich wie für sich infizieren unddas ist nur ein basis modell es gibt bestimmten dutzend erweiterungen davon wo man halt mehr einzelne.Parlamente hat also dann für was er sich infiziert aber noch nicht ansteckend und ansteckenund dann infiziert noch aber nicht mehr ansteckend und so das kann man also sagen einmal auf der ebene kann man da differenzieren aber viel wichtiger ist halt noch.Die frage jetzt der der räumlichen einheiten an der an der berlin beispielsweise das istdie gruppe des.
Tim Pritlove 0:08:33
Also umwelt humboldt-universität hier in berlin eine der drei großen universitäten in berlin.
Pavel Mayer 0:08:39
Genau und da gibt es halt das sogenannteps das ist die research komplex systemsgroup und die sendung sagen der der hauptpartner vom robert koch institut wenn es jetzt darum geht die zahlen zu analysieren und die habenhalt außerdem noch sehr komplexe bewegungsmodulen und.Das ganze läuft halt so im wesentlichen auf landkreis ebene abwenn es um deutschland geht beziehungsweise auch in einem welt maßstab haben die dann daten.Wie viel flugverbindungen wieviel passagiere von wonach wo direkt auf der welt.Anreisen und machen halt dann auf diese weise sagen sowohlräumlich als auch in den einzelnen kompartimente fahren sie dann halt diese simulation wieviel jetzt einmal personen mit welchem in kontakt.Weil sie in der nähe leben oder sollte weil es da verkehrsverbindungen gibt weil die leute pendeln und und so und darauf basieren dann halt die komplexen.Vorhersage modelle die dort gefahren werden und.Wenn wir jetzt dann schon gleich in die probleme mit diesen modellen einsteigen das fängt halt schon mal damit an dass mansondern modell nicht einfach auf 'ne ganze auf eine ganzes land wie deutschland.Anwenden kann beziehungsweise ist es so dass wir nur eine person hast oder.Jetzt infiziert ist dann ist die nicht physikalisch nicht in der lage mit achtzig millionen menschendie gleichzeitig anzustecken oder in in absehbarer zeit das heißt es gibt irgendwie da so einen wertwie groß ist denn jetzt so eine so eine gruppe die sich da einstecken können und da kommt man dann sagen auf eine zahl von fünfzehntausend interessanterweise die in vielen fällen so zutrifft so die man dann so als als gruppe betrachtet und.Die modelle außerdem sind halt sehr sensitiv auch gegenüber der größe dieser gruppe also es ist so dass man hat in so einem modell dann eben eine ganze reihe von parametern im einfachen modell.Sind das eben nur im wesentlichen zwei parameter wo es wo der eine beschreibt gutwie ansteckend ist das ganze und der andere wie lange dauert halt so eine ansteckungdas ist natürlich eine sehr sehr starke vereinfachung aber diese konstanten wenn man die jetzt auf eine andere auf eine gruppe.Einer anderen größe irgendwie anwendet rein numerisch kann man die werte nicht ganz so einfach skalieren weil sich diese differentialgleichungen da halt anders verhalten das heißt es fängt schon mal damit anwas nehme ich eben als anfangs wert für september also wie groß ist meineanfängliche population und man kann da sagen okay ich setze jetzt als eins und rechne das dann hoch aber wie gesagt dann.Stimmen die ganzen konstanten nicht und bei achtzig millionen geht's auch nicht sondern man muss da irgendwas dazwischen nehmen und dann gucken wie die werte.Unddas zweite problem ist dass die ganzen modelle sehr sehr empfindlich sind gegenüber dann den richtigen parametern wenn die sich nur ein bisschen.Verändern dann hat das erhebliche auswirkungen auf das endergebnis und.Was mir halt auch nicht so ganz gefiel was man jetzt machen kann wenn man jetzt so einmodell nimmt und das auf existierende zahlen versucht zu meppen oder zu parametrieren kommen da ziemlich wüste parameter bei raus abhängig vom landso da hat man dann beim einen land hat man dann irgendwie einen millionstel als als pferd und bei demanderen für den parameter und das ist natürlich dann schon so ein bisschen da fragt man sich okay was sagen diese parameter jetzt eigentlich aus.Bin mit den modell nicht ganz glücklich obwohl man da sehr sehr einfachsehr sehr schnell mit dem ein moderner mathematik software da kann man halt einfach ein paar differentialgleichungen eingeben und dann sagt man löse mir jetzt dieses differentialgleichungssystem und.Die kurven an das ist halt sehr einfach und dann kann man auch mit entsprechenden anderen optimieren wiederumversuchen die ergebnisse halt passend zu machen für aktuelle echte zahlen und dann kriegt man haltzwar passende kurven aber die parameter sehen dann halt sehr sehr seltsam aus bei den modellen.
Tim Pritlove 0:13:38
Gibt's da noch andere modelle außer diesem modell oder ist das im prinzip so die mutter aller simulation an der stelle.
Pavel Mayer 0:13:46
Ja also ich bin da auf nicht viel anderes gestoßen so was ich aber selber gemacht habe.Ist auch etwas was angewendet wird undunter gewissen annahmen deutlich einfacher und und schöner funktioniert und zwar folgen halt solche infektionenwenn man die gesamtzahl der infizierten sich anschaut dann folgen sie einer sogenannten logistik cafeso eine logistische kurve ist das ist eine etwas erweiterte sieg multifunktion also die fängt halt langsam an steigt dann exponentiell angeht dann in einer etwas gerade phase über um sich dann wiederum zu verlangsamen und wieder und sagen wieder in die horizontale abzuknipsen und dann irgendwo auf einem bestimmtenniveau zu verharren und ich hatte halt auch wie vermutlich alle erst mal angefangen mit ich sag mal einfach malden exponenten am anfang zu berechnen zu gucken was macht so eine einfache exponentiell funktion und da sieht man dann halt sehr schnell dass die halt.Passt dass man da zwar für die nächsten drei vier fünf tage vielleicht durchaus auch mit einer exponentiell funktion zu bestimmten zeiten ganz gute werte hinkriegt aber sobald es ein bisschen länger reingeht braucht man dann halt eine logistik funktion eine bei der sich der exponentenquasi abschwächt und dann bin ich halt hingegangen und dachte mirgut dann gucke ich mal nehme ich doch mal die china daten und versucht da mal eine logistik fraktion drüber zu meppen und es ging erstaunlich gutalso die passte halt einfach und dachte mir okay wenn's für china passt passt vielleicht auch für andere länder und habe dann halt angefangen insbesondere ja deutschland unditalien noch die die zahlen jeweils zu zu zu fitten und zu tracken und zu gucken was die denn dann rauswerfen.
Tim Pritlove 0:15:50
Und das hat gepasst oder nicht so.
Pavel Mayer 0:15:52
Und ja also erstmal die interessante erkenntnis war auch dann zu sehenwas ich da gemacht habe für die china datenist ich habe mir quasi slider gemacht wo ich halt in der zeit zurück gehen kann und dann sagen vorhersagen gemacht habe oder simuliert habe wie wäre denn jetzt für china meine vorhersage an dem und dem tag gewesen und wie ist es dann tatsächlichausgegangen und daraus sieht man dann dass man das halt deszu einem frühen stadium man zwar so eine woche oder.Ja eine woche vielleicht ganz gut vorhersagen kann aber dass die daten keinerlei information erhalten wann denn die kurve wiederum abflachtdas kann man halt erst merken wenn die kurve beginnt abzuflachen und da habe ich dann halt auch auch geguckt.So sind wir jetzt die entscheidende frage ist unsere kurve flach die jetzt wirklich ab weil es gibt aufgrund der problematik der datenerhebung wo wir vielleicht auch noch auch noch zukommen sollten passieren da.Andere effekte die da in die in die zahlen eingehen also es fängt erst mal damit an dass sie teilweise verzögert.Das was sich am wochenende sich die fall bearbeitung staut und an die wochenendezahlen regelmäßig niedriger waren dann entwickelt sich die test kapazität auch die bleibt nicht gleich das heißt.Da ist die frage misst man zu einem bestimmten zeitpunkt also wenn die test kapazität überlaufen ist dann zeigt die kurve halt nicht den verlaufder tatsächlichen erkrankungen an sondern bei den der ausbau der test kapazität.
Tim Pritlove 0:17:47
Wie man das jetzt in den usa natürlich gerade wunderbar sieht da wurde halt am anfang im wesentlichen überhaupt nicht getestet und als dann getestet wurde wurde mit etwas getestet was nicht gut funktioniert hat und jetzt haben sie so ein bisschen den salat und.Vorhin gerade nochmal den trosten podcast wurde ja auch nochmal dargelegt dass man mittlerweile durch biologische analysenganz gut nachweisen kann dass die viruserkrankungen die halt jetzt in den usa stattfinden mit sehr großer wahrscheinlichkeit direkt aus china kamen und von daher wohl auchsehr früh stattgefunden haben also man kann ja in der moderationdir weiterhin stattfindet der wären ganz gut ablesen wann wo sich was hin verbreitet hat also nicht unmittelbar aber mittelbar indem man halt ein bisschen noch drumherum forscht und dannkann man eben solche dinge abziehen und jetzt gehen natürlich die zahlen nach oben weil jetzt überhaupt erstmal richtig getestet wird aber das bildet ja sozusagen nichtdie jetzige entwicklung ab sondern das ist ja im prinzip eine nachgezogene entwicklung die überhaupt erstmal damit zu tun hat dass dass man sich um das problem überhaupt erst kümmert.
Pavel Mayer 0:18:53
Also es ist haltschon so dass wenn man das das das testen ausweitet dass man dann natürlich plötzlich möglicherweise einen schnelleren anstieg in den zahlen sieht als er tatsächlich real stattfindet weil halt plötzlich mehr getestet werden und es dadurchmehr wird und natürlich ist klar dass niemals alle leute getestet werden sodass es.Immer 'ne dunkelziffer gibt sie frage wie wie viel mal mehr leute sind sind infiziert als in den offiziellen zahlen.Da kann man auch gewisse abschätzung machen so eine abschätzung die man machen kann die ich selber auch nachvollzogen habe ist über die anzahl wiederum der toten weil sagen es.Mit ziemlicher wahrscheinlichkeit unterschiede gibt bei den dunkelziffernvon corona toten und von infizierten weil bei.Toten ist es zum beispiel so dass dort nur zählt und es ist machen fast alle länder so.Wer vorher zu lebzeiten positiv auf corona getestet wurde zählt als corona toter wenn jemand stirbt ohne dass es einen test gekriegt hat wird halt nicht getestet also in der regel testen wir keine toten.Jetzt ist es aber so dass statistisch auch angeguckt etwa die hälfte aller menschen in deutschland in krankenhäusern stirbt so das sind aucheine ziemliche menge also ich glaube.So dreieinhalb bis viertausend am tag sterben in deutschland überhaupt und die hälfte davon in krankenhäusern so jetzt kann man.Also davon ausgehen aber das also zumindest tote werden halt erfasst so wenn die hälfte von denen in krankenhäusernstirbt kann man wiederum auch aus davon ausgehen dass einen großteil derer die in krankenhäusern sterben aucherfasst werden natürlich auch nicht alle so aber im moment kann man sagen klar wenn jemand eingeliefert wird mit.Symptomen allein schon zum schutzder anderen patienten und so wird natürlich dann getestet das heißt man kann generell davon ausgehen dass die dunkelziffer bei der zahl der toten geringer ist beziehungsweiseeine gewisse obergrenze hat und wahrscheinlich irgendwo unter zwei liegt weileben wie gesagt krankenhäuser aber in der größenordnung von zwei so des weiteren ist es so dass die todesfälle halt.Später in die statistik eingehen als die infizierten sich infizierten so nach zehn bis vierzehn tagen nach der infektionwährend die toten nach ja so siebzehn bis vierundzwanzig tagen ungefähr gezählt werden und aus dieser sagen zeitlichen verschiebung kann man dann wiederumverhältniserrechnen wenn man weiß wie der unterschied zwischen dieser zeitlichen verschiebung ist wie sich die die dunkelziffer dort unterscheidetund da kann man zumindest sagen weil man da wiederum die sagendie sterbe dauer die durchschnittliche nicht genau kennt beziehungsweise.Die sich auch in verschiedenen ländern unterscheiden kann und je nachdem welche population da gerade erkrankt welcher teil jetzt ältere oder mehr jüngere und so aber was man auf jeden fall machen kann.Damit ist die dunkelzifferzwischen ländern zu vergleichen und da kann man mal sagen dass in italien die dunkelziffer bei den zahlen deutlich höheralso vermutlich zwei bis vier mal so hoch wie in deutschland und dass die in deutschland irgendwo zwischen zwei und vier liegt aber wahrscheinlich eher irgendwo in der in der gegend bei zwei und.Die ist halt auch nicht konstant die dunkelziffer sondern die verändert sich halt auch im laufe der zeit und macht halt auch eine interessante kurve durch wenn man da vergleicht.Geht nämlich am am anfang sagen geht die dunkelziffer.Hoch weil noch nicht so viel getestet wird und die infektion sich schneller ausbreitet als man testet dann irgendwann geht es testen los die test kapazität wird hochgefahren und dannbeginnt die dunkelziffer zu sinken und muss eigentlich aufvielleicht nicht ganz eins aber deutlich unter zwei in die nähe von eins kommen wenn man das alles in griff kriegen will weil es funktioniert natürlich nicht wenn jetzt dreiviertel meinen infektionen sich außerhalb dessen stattfinden was man irgendwo trägt aber nichts desto trotz kann man dennoch mit den zahlen die erhoben werdenschon eine ganze menge machen weil wir eine ganze menge informationen rausziehen.
Tim Pritlove 0:23:56
Jetzt haben wir schon angesprochen diese ganzen modelle haben.Zahlreiche parameter und welche parameter sie haben das ist dann sozusagen auch extrem abhängigvon dem angesetzten modell oder kann man halt immer wieder andere faktoren mit reinbringen paar sachen haben wir ja schon angesprochen ich war also wie groß ist überhauptder bereich den ich potenziell infizieren kann das verhält sich natürlich in der stadt anders als auf dem land und es hat auch sagen wir mal sehr viel mehr damit zu tunob man auf ein land schaut was sagen wir mal wo das öffentliche leben sehr viel mehr auf straßen und plätzen und märkten und ähnlichem stattfindet ja also dasbetrifft vor allem südeuropa da ist es wärmer ist das ist einfach eine ganz andere umgangs kultur auch am start so faktoren wie wie oft leben ältere leute noch zuhause.Und vermischen sich sozusagen dann auch über die generation miteinander das ist definitiv ein faktor der in italien auch immer wieder erwähnt worden ist.Und die andere frage ist natürlich auch woher kommen dann sozusagen diese zahlen die diese parameter auch.Befüttern welche quellen haben sich denn jetzt.Herausgebildet in den letzten wochen aus denen man jetzt solche modelle überhaupt nähren kann inwiefern sind die global auch vergleichbar was benutzen wir in deutschland etcetera.
Pavel Mayer 0:25:21
Okay ich habe da jetzt kein globalen überblick aber ich kann erstmal erstmal vielleicht zu deutschland.Ist es so dass die gesundheitsämtern für die datenerhebung zuständig sind das heißt wenn jemand erkrankt alsojakob ist halt eine meldepflichtig krankheit das heißt wer erkrankt ist auch verpflichtet und nur sie ärzte wenn die das feststellen oder einen verdacht haben dann wird das dem gesundheitsamt erstmal gemeldet auch wenn man dann kontaktehatte ich habe das ja auch in der familie weil jemand einen kontakt zu einem infizierten hatte habe ich das haltziemlich direkt mitbekommen da wird man dann kontaktiert auch vom gesundheitsamt muss sich erstmal in selbst eine begeben und je nachdem ob man man symptome zeigt oder nichtund wie die art des kontakt des war gibt es eine kontakt klassifizierung wie lange man mit jemandem im kontakt war und.So und wie nah und so da gibt's so ein paar kategorien und je nachdem wie die ausfällt wird man dann getestet oder nicht so im zweifelsfall wird man nicht getestet genau und dann.Läuft das testenfindet natürlich in labor statt das heißt entweder einen arzt zu dem man gegangen ist entnimmt halt eine probe da sind halt wattestäbchen mit denen dann aus dem rachen im einfachsten falle abstriche gemachtwerden am besten durch die nase was soll's für mich unangenehm ist aber egaljeden fall und diese abstriche werden dann an einem labor gesendet so per post imwesentlichen oder per per kurier und die labore je nachdem ob die für tests selber als ob die selber kult tests machen oder was am anfang nicht der fall war die meisten haben keine tests gemachtneben dir diese proben und schicken die an ein anderes labor weiterda dauert so einen lauf mehrere stunden so fünf bis sechs es wird immer ein bachelor gemacht die abstriche müssen halt vorher auf aufbereitet werden und dann ja wie gesagt.Läuft es durch und so nach sechs bis acht stunden hat man schon so ein bach von ich weiß nicht vierhundert,tests oder so hat man dann durch und man sammelt natürlich erstmal die tests die im laufe des tages reinkommen die werden dann irgendwannimmer wenn genug test da sind wird halt so einen lauf gestartet und wenn der lauf dann durch ist geht halt das testergebnis so an den arzt undans gesundheitsamt und die frage ist wie geht er dahin so teilweise eben nur per.Per post oder per irgendwie begleitschreiben und das gesundheitsamt wiederumda muss man mitarbeiter sich sich dann wiederum auch auswerten und gegebenenfalls dann auch wieder die person kontaktieren und die kontaktperson gut dies wird wurde schon parallel ermittelt aber dann den kontaktpersonen mitteilen eventuell obder test positiv war oder nichtund dann wird das ganze aggregiert von den ganzen gesundheitsämtern und geht dann auf landesebene hoch und die länder melden dann.In der regel entweder ein pressekonferenzen oder haben dann selber irgendeine webseite wo sie dann.Das ergebnis veröffentlichen und es gibt aber auch ein zentrales meldesystem so wo die gesundheitsämtern die daten.Eingeben müssen so das funktioniert am anfang auch erstmal nicht so gut ich weiß nicht ob das am system lag oder weildie leute nicht wussten wie man's bedienen kann oder einfach keine zeit hatten das zu bedienen jedenfallshat es aber irgendwann nachdem sie auf allen möglichen wegen halt daten mitgeteilt gekriegt haben irgendwann gesagt okay das ist uns zu viel wir nehmen daten jetzt nur noch.Entgegen es gab da so eine übergangszeit von der woche und jetzt läuft esso einigermaßen nicht immer so manchmal vorzimmer noch aus technischen gründen oder soschafft dann schon mal ein land irgendwie keine daten zu melden und man sieht halt es ist halt ein deutlicher nachlauf es dauert zum teil tage bis die daten die schon in den gesundheitsämtern vorliegen und auf den ländern ebene vielleicht schon vorliegen bis die dann in das zentrale erfassungsstelle mwandern und so ergeben sich dann auch die unterschiede in den zahlen es gibt einmal das robert-koch-instituttrack nur zahlen und das sind die die ich auch benutze die halt offiziell beim robert-koch-institutgemeldet und als labor bestätigte fälle dort gemeldet werden während andere quellen.Dazu übergegangen sind die daten direkt von verschiedenen websites der einzelnen länder zu scraperund damit zeitlich ein bisschen früher dran sind als das robert-koch-institut deswegen sind die zahlen halt dort typischerweiseetwas höher und da gibt es im wesentlichen zum einen kollaborationen von medien anes gibt bestimmte firmen die das professionell machen und es gibt jetzt gerade in den usa halt auch quellen weil es in den usa sowas wie die gesundheitsämtern nicht.Gibt in dem sinne oder ja da funktioniert es wohl ein bisschen anders und da sind in den usa praktisch die einzigen zahlen die die halt vonmal freiwilligen organisationen zusammengetragenwerden und veröffentlicht werden aus sagt auch hunderten von countries und auch mit scraper von webseiten und mit teilweise mit eingeben von hand und und so.
Tim Pritlove 0:31:21
Da ist ja vor allem diese john hopkins universität.
Pavel Mayer 0:31:25
Johns heißt ja immer ich mache auch immer denselben fehler die halt johns hopkins.
Pavel Mayer 0:31:31
Genau ja die sind die sagen dort quasi an der vorderen front und tragen eben auch daten zusammenaber wie gesagt da gibt's halt ein paar organisationen die eigentlich noch fast bessere zahlen haben wobei es.Wenn ich sagen egal ist auf welche zahlen man guckt aber wenn man welche vergleicht muss man halt sollte man die aus derselben,quelle vergleichen und seine analysen drauf machen das ist so der der punkt und ich hatte mich relativ früh dahin verlegt sondern die offiziellen daten zu nehmen die auch schön in der wikipedia aggregiertwerden undja darf vielleicht auch gesagt ich will jetzt nicht undankbar sein die leute haben alle wirklich viel um die ohren aber ich bin ein bisschenunglücklich über den stand der datenliberalisierung in deutschland oder dem was öffentlich.Bereitgestellt wirddas fängt schon mal damit an dass gutes liegt jetzt daran dass gesundheitsämtern die interessiert nur ob jemand krank ist nicht ob jemand.Gesund ist das heißt wenn du ein negativer test.Erfolgt war es bisher so dass das halt schlichtweg nicht gemeldet wird weil wozu sollte man.So war die logik jemand melden der nicht krank ist so.
Tim Pritlove 0:32:55
Naja.
Pavel Mayer 0:32:56
Ist halt natürlich die zahl der durchgeführten tests und der anteil der positiven tests daran ist natürlich wichtig um beurteilen zu können wie es die positiven quote also es wäre eine unglaublich wichtige zahl diese zahlen.Das zwar auch bei den gesundheitsämtern ich gehe davon aus dass die auch jetzt nach und nach aggregiert werden aber wir haben dabisher immer nur so momentaufnahmen wo dann in pressekonferenzen dann gesagt wird ok und an dem und dem tag oder in der und der woche haben wir jetzt so und so viel tests durchgeführt aber.Wenn man sich anguckt wie das inin südkorea aussieht zum beispiel was da gemeldet wird hätte ich mir für deutschland gewünscht da ist auch gemeldet wieviel tests wurden jeden tag durchgeführt wie viel leute wie viel tests wurden entnommen also wie lange ist die pipeline von leuten die gerade getestetwird sodass man halt dort wesentlich besser das ganze sehen kann plusdie zahl der todesfälle und wie viel davon sich in behandlung befinden gerade ein wesentlich größere offizieller datenschatz einmal als wir ihn zur verfügung haben und eigentlich.Wäre es wahrscheinlich überhaupt kein problem ich kann mich da auch täuschen aber ich gehe mal davon aus dass halt dieses zentrale erfassung system wo die gesundheitsämtern ihre daten eintragendas dahinter eine datenbank ist so und wie wir alle wissenes ist jetzt nicht so schwierig sondern dump aus einer datenbank zu ziehen oder einfach eine wahrscheinlich eine einzige abfrage auf die tabellen in der datenbank und.Man könnte so dinge.Ja selbst wenn man natürlich die privatsphäre waren will und so aber ich vermute irgendwas zwischen ich sage mal fünf minuten und einem tag die man bräuchte um so etwas einzurichten das halt auszügeaus dieser datenbank einfach online gestellt werden als csv datei mit einem eintragfür jeden fall wann ist der fall reingekommen und mit ein paar informationen muss gar nicht sein wer das ist und so das würde haltschon ein ziemlich weiterhelfen wenn es sowas gäbe aber ja.Gibt es halt nicht so haben wir halt pech gehabt dass wir kriegen sind halt.Einige wenige akkumuliert zahlen die dann runter gebrochen werden noch auf bundesländer und das wars natürlich haben jetzt.So hat das robert-koch-institut wesentlich bessere daten und ich hoffe und gehe davon aus dass dort eben am am am.So ist es an der an der an der dass die auch zugang zu mehr und besseren und aktuelleren daten haben aber jaich finde das im vergleich zu anderen ländern einfachdeutlich unbefriedigend und vor allem bei den letzten zehn jahren ist die rede von open data und kaum irgendwie passiert mal was wo es wirklich wirklich wichtig wäre die daten zu haben irgendwie ist von openso ziemlich gar nix zu sehen gerade also nicht mal es gibt nicht meine.Blöde zeitreihe zum runterladen jetzt offiziell ja das heißt man muss halt entweder in die wikipedia gehen und dort die daten abschreiben oderdie täglichen berichte die als pdfsverfasst sind sich sich sich anschauen oder so also es ist schon ja eigentlich nicht zweitausendzwanzig würdig so.
Tim Pritlove 0:36:39
Ja da.Das recht sich natürlich jetzt dass das dass das thema halt weitgehend ignoriert wurde wie du schon sagst das war da hatte man viel schöne wetter rhetorik das war so open data das ist dann halt sobisschen wie das klatscht man sich mal ganz gerne auf die stirn wenn wenn die rede ganz gut klingen soll und dass man das irgendwie alles gerne machen möchte etcetera aber das bei mir auch immer so ein so ein wiederkehrender rand.Ich habe immer so das gefühl dass einfach die kultur.Also die ganze arbeitskarten digitalkultur da einfach noch nicht mitgezogen hat dass das ist einfach kein verständnis dafür gibt dass es eher als etwas angesehen wird so als ja das wäre ja schön wenn man da mal hinkommen könnte unddas würde sich bestimmt gut machen aber sich nicht wirklich in der rennt dieser gedanke durchgesetzt hates ist absolut essentiell dass man das tut und selbst für datensammlung fürdie man jetzt in irgendeiner form nicht vorausgesehen hat das kann man ja jetzt hier sozusagen was du gerade dargelegt hast welche zahlen werden nicht erfasst etcetera klar gutdas kann man dann irgendwann verstehen und dann dann dann ändert man vielleicht seine vorgehensweise aber dann mangelt es einfach andaten formaten da mangelt es einfach an tools da mangelt es einfach an möglichkeiten diese informationen auch schnell in die welt zu bekommen ja es geht ja gar nicht mehr nur darum dass die daten alsoerstmal die daten müssen erfasst werden das ist schon mal das allererste ganz klar das ist ja von open data erstmal unabhängig,wann generiert die man oder man wirft sie nicht weg ja also das sozusagen daten die auch da sind auch in irgendeiner form immer irgendwie im zugriff sind dannträgt man sie zusammen dann bietet man sie an und dann setzt man sie aber nicht auf webseiten.Also das kann man auch machen ja und auch gerne pdf-dokumente erzeugen und allesaber solche daten wollen dann eben auch live abgefragt werden und das gibt es halt dann auch nirgendswo dass so ein gesundheitsamt diese daten einfach in maschinen lesbarer form vorliegt über einen klar definiertes.Über das dass man gar nicht erst groß gucken muss wie funktioniert denn das hier sondern es ist einfach klar man kriegt solche epidemiologische datenin der zeit kann ich jetzt mal eben abfragen beim r k i über dieses protokoll.Ja was im idealfall auch noch so ein bisschen selbstauskunft betreibt das heißt ich könnte mit einer software daran gehen und sagen so hör mal ich interessiere mich hierfür neunzehn ja also für diese.Epidemiologische betrachtung dieses zahlenmaterial was hast du denn so und dann antwortet die webseite erstmal mit.Ich könnte dir folgende daten geben und die sind folgendermaßen klassifiziert und ich habe diesen parameter und der heißt so der ist von dem typ und so weiter und ich habe daten von bis so und dann geht man halt hin und sagtokay alles klar gib mal her mich interessiert des des des des des des des und das hätte ich jetzt ganz gerne mal für die letzten.Fünf monate fünf jahre was auch immer bei grippe könnte man ja im prinzip ewig zurückgehen und dann wäre das ein rüstzeug für leute die einfach auch neue ideen haben die vielleicht neue studien machen wollen et cetera oder eben auch nur für tageszeitungen um das ganze dann eben in so eineöffentlichkeit kompatiblen form zu gießen.
Pavel Mayer 0:39:56
Also bei den leuten jetzt die sagen dass das tracking freiwillig machenhat sich so ein bisschen etabliert die daten halt entweder als excelbereitzustellen was auch schon mal nicht schlecht ist oder als google only so das ist schon mal ungefährtausend mal besser als die daten abzug tippen von irgendwelchen webseiten oder oder scripten zu müssen.Oder halt in typischerweise csv formaten oder als irgendein anderes,ein dateiformat aber meistens csv und das dann jeweils bei gitta einzuchecken so täglich zu aktualisieren.
Tim Pritlove 0:40:42
Also csv so ein ganz normales text basiertes einfaches komma getrennt das format was man einfach auch so angucken kann und dann versteht man auch schon was ist aber was man auch relativ leicht eigentlich mit jeder pur mir sprache irgendwie eingelesen weiterverarbeitet bekommt.
Pavel Mayer 0:40:55
Genau ja excel oder mitbeliebigen anderen ja tabellenkalkulation programm oder auch ja mit peißen skripten oder so das ist ja und aber dieser interessant diese kombination halt dann ausalso geht hab spielt auch also es gibt etliche gitarre tories wo gerade aktuell eben gescreente und konsolidieren daten oder offiziell gemeldete daten dann aggregiert und.Committed werden so dass man da relativ schnell sich eine pipeline aufbauen kann und dann einfach sagen kann.
Tim Pritlove 0:41:36
Da bediene ich mich mal von.
Pavel Mayer 0:41:37
Da bediene ich mich da up date ich meine position dann einfach geht pull und dann habe ich die neuesten zahlen wenn ich mich da drangehängt habe.Also man braucht da jetzt gar nicht.Eigentlich noch nicht mal groß hingehen und it-entwicklung zu betreiben um den paradiesischen zustand hinzubekommen den du vorhin geschildert hast so ja.
Tim Pritlove 0:42:02
Paradiesisch naja also.
Pavel Mayer 0:42:06
Also im vergleich zu.
Tim Pritlove 0:42:08
Das noch paradiesisch klingt das ist das schlimme ja also das ist mein gott.
Pavel Mayer 0:42:13
Ja definitiv definitiv ja also das ist das da kann man vielleicht sagen da das könnte deutlich besser.Werden dass das ganze und gut im nachhinein ich gehe davon aus dass haltdie daten irgendwo aufbewahrt werden und das hinterher sagen auch genug daten zur verfügung stehen wobei die andere sache ist es jetzt nicht nur es ist nicht nur mit mit statistiken getanso sondern man will natürlich auch dass die mediziner jeweils studien fahren also so dinge wie wie hat sichdie virus konzentration in einer gruppe von patienten über die zeit entwickelt wie lange sind die ansteckend wie ist der ausgang wie viele schwere komplikationen leichte komplikationen dann wenn wirnichts dazu kommen dass das medikamentös behandelt wird wie schlagen vielleicht jede medikamente oder andere,behandlungsmethoden eigentlich an und so also all diese daten hoffe ich.Und gehe davon aus dass da einiges erhoben werden wird was ich aber so gehört habe ist schon dass die besten datenbisher aus einer zeit stammen also entweder aus china kommenso oder hier bei uns aus studien wo alles noch ein bisschen entspannt war wo die patientenzahlen noch niedrig waren und die ärzte noch zeit hatten sich ausführlich mit einzelnen patienten zu beschäftigen ich hoffe dass das jetzt sagen auch zumindest an einigen krankenhäusern die kapazitätennach wie vor da sind um nicht nur jetzt die patientenzu versorgen sondern auch erkenntnisse zu gewinnen die man braucht um die krankheit dann zu bekämpfen oder besser bessere entscheidungen treffen zu können.
Tim Pritlove 0:43:54
Dann lass uns doch mal schauen auf was jetzt diese ganzen gesammelten daten und die modelle derzeit denn so.Aussagen kannst du auch noch mal einen kurzen blick zurückwerfen inwiefern das was du vor lange ist es her dass wir uns zuletzt unterhalten haben vor ein paar tagen was das sozusagen alles.Wie viel das mit der wahrheit und fehlt dann zu tun hatte und was ich aus deiner perspektive derzeit da so herauslesen lässt.
Pavel Mayer 0:44:26
Ich würde aber gerne einsteigen und sagen mit den offiziellen modellen dass wir erst mal einen blick.Auf die kurz kurz werfen so und da hat es auch ziemlich lange gedauert.Bis ich die gefunden habe weil die wurden auch nicht so groß etwa heißtund wie gesagt gerade also diese diese webseite da an der von der vom vom csd wo sie halt tägliche vorhersagen laufen haben imprinzip für ziemlich viele länder für fast alle länder nicht geguckt sechzig aber ich würde sagen so sechzig achtzig länder oder so und.Das ist natürlich schon ja nett so dass man da wirklich alle länder im zugriff hat und.Was sie halt machen wie gesagt ist halt sie fahren halt dieses serie serie xso wo sie dann versuchen die parameter aus den bisherigen daten zu errechnen und das dann eben weiterlaufen lassen und gucken wo es dann hinläuft so.Der punkt ist dass sie halt irgendwann festgestellt haben okay eigentlich.Können wir nur die nächsten sechs tage so richtig vorhersagen nach sechs tagen läuft unsere fehlerquote einfach ist halt so hoch der errechnete fehler das ist halt das halt mehrkeinen sinn macht dass es sozusagen deren sicht und sie haben dann auchauf den entsprechenden vorhersagen ist auch interessant also man kann zwischen logarithmus und linear hin und her schalten ich finde die geniale ansicht ein bisschen hilfreicher wenn man in die zukunft.Guckt da kann man dann genauer sehen so und jetzt konkret für deutschland.Sagen heute und mit einem update also basierend wurde am einunddreißigsten märz gestern um dreizehn uhr.Zweiundfünfzig oder wir haben heute haben wir heute überhaupt.
Tim Pritlove 0:46:42
Heute ist der einunddreißigste märz das habe ich aber mich am anfang nicht gesagt dass bestraft sich in dieser berichterstattung enorm.
Pavel Mayer 0:46:49
Okay von heute dreizehn uhr zweiundfünfzig sagen es dort die vorhersage und mit.Einer achtundsechzig prozentigen.Wahrscheinlichkeit also konferenz intervall von ist ein bisschen anders wahrscheinlichkeitsrechnung ist,würde ich sagen die die hölle aber es ist ein wahrscheinlichkeitsrechnung ist oft nicht intuitiv so in sechs tagen werden wir dortnach deren vorhersage bei hundert rund hundertfünftausend infizierten liegen wir liegen heute bei siebenundsechzigtausend undmit einem achtundsechzig prozent konferenz intervall könnte esaber auch so niedrig wie neunundachtzigtausend oder so hoch wie hundertdreißigtausend sein also man sieht schon sagen für sechs tage sagen die ober-und untergrenze ausgewiesenschwankt halt von vierundachtzigtausend bis hundertdreißigtausend das ist natürlich für eine sechs tages vorhersage schon mal einekrasse fehlerquote wenn man jetzt achtundneunzig prozentsicherheit haben will dann ist es zwischen achtzig und zweihundertzwanzigtausend in sechs tagen.Wenn ich will das jetzt nicht niedermachen ich finde es gut dass sie's überhaupt.Machen das überhaupt jemand hingeht und irgendwie diese vorhersagen macht aber es ist ein bisschen unbefriedigend weileigentlich kann man jetzt nicht so viel aus diesen zahlen rausziehen vor allen dingen für die für die nächsten sechs tage zumal man für die nächsten sechs tage in der regel die zahlen auch ganz gut.Mit viel einfacheren methoden abschätzen kann gut sie sagen auch okay die vorhersage ist halt.Vergleichen das mit der wettervorhersage,ja eigentlich ist es ein schlechter vergleich mit der wettervorhersage finde ich aber deren punkt war okay wir wissen ja nicht welche maßnahmen jetzt eingeführt werden in der zukunftdie dann halt die zahlen entsprechend beeinflussen der punkt ist man weiß,aber da die zahlen mit zehn tagen rückwirkend kommt hat man eigentlich eine gewisse vorstellung davon ob und welche maßnahmen.Eingeführt worden man weiß natürlich nur noch nicht wie sie sich auswirken aber man kann man hat zumindest diese information da da ist was passiert so das ist die sozusagen die eine sache deren simulation.Ignoriert das halt komplett sowie ich sage mal meine auch aber meine macht ein paar andere andere annahme dass es sagen man vorhersagen.An wirklich konkreten vorhersagen das einzige was ich gefunden habe am prozess der berlin und finde es ist schick gemacht grafisch und sound man muss auch sagen fairerweise das was das sonst so macht ist halt viel viel komplexer.Das hat halt diese diese ganzen komplexen netzwerk daten und haben jetzt noch.Zum beispiel auch daten bekommen über die wanderungsbewegung jetzt mit also handydaten von verschiedenen professionellen providern die halt kommerziell daten der telekomauswerten und tracken das kann man sich in etwa so vorstellen das läuft auf landkreisebene das heißt die kriegen dort zahlen aggregiert wie viele haben sich an einem tag von dem landkreisin einem anderen landkreis bewegt so also sie haben sagen so ein bewegungsmuster keine ein sondern regierte daten so wer ist heizt sich eigentlich von wonach wobewegt.
Tim Pritlove 0:50:46
So pendler pendler überblick.
Pavel Mayer 0:50:47
Genau pendler oder überhaupt reisende und so die ja.So also diese diese zahlen haben die und und darauf rechnen die normalerweise plus andere dinge dieses modell was dort jetzt die vorhersagen macht basiert tatsächlich nurauf den nackten zahlenwerten sowie mein modell auch und versucht halt das modell mit den richtigen parametern initialisierung dann bisschen weiter.Laufen zu lassen und ich weiß auch nicht weil ich nicht weiß wie die vorhersagen wie die alten.Ausgesehen haben insofern ist es jetzt nicht ganz einfach.Zu gucken überschätzt oder unterschätzt das modell oder gibt es da also systematiken was ist da was ist da falsch und wie gesagt meine fünf tage vorhersage macht das jetzt nicht.Ich mache das jetzt nicht den den den großen unterschied wahrscheinlich aber ja konkret vielleicht noch wenn wir uns da mal.Italiennochmal auch im vergleich anschauen da sind wir derzeit bei rund hunderttausend und da prognostiziert das modell hundertdreißigtausend für in sechstagen und ja es können aber auch sagen.Hunderttausend sein oder zweihundertzwanzigtausend wenn man sagen achtundneunzig prozent sicher sein will oder hundertzwanzig bis hundertfünfzigtausend für das achtundsechzig prozent konferenz intervall.
Tim Pritlove 0:52:25
Man muss aber dazu sagen die ganzen zahlen die wir reden jetzt von infizierten die insgesamt gezählt wurdenwas da ja beispiel nicht drin ist ist wie viele sind davon gesund geworden haben werden kein problem mehr haben und so weiter die zahl ist natürlich.Wächst natürlich auch am laufenden meter sprich dieses fenster von potenziell bedrohten von denen man weiß.Ist halt kleiner als dass diese zahl das irgendwie suggeriert weil man das immer so wahrnimmt mit so hunderttausend ja also man sieht sozusagen sofort hunderttausend leute vor sich die irgendwie krank wie zombies durch die gegend laufen weder sind die zwangsläufig krank noch sind sievielleicht überhaupt noch bedroht.
Pavel Mayer 0:53:09
Ja allerdings kann man sagendass selbst wenn es jetzt keine quarantäne gebe so ungefähr ein viertel der leute so schwer erkranken dass sie halt arbeitsunfähig sind sound eigentlich so wahrscheinlich die hälfte aber sagen wir fünfundzwanzigprozent so zeigen ernste symptomesind auch gefährdet immerhin was halt auch unschön ist wenn es einen wirklich schlimm erwischt hinterlässt es auch langzeitschäden also es ist auch nicht so schöninsofern möchte man das nicht nicht wirklich haben weil wir wollen ja auch bisschen dafür kritisiert dass wir ein bisschen salopp gesagt haben okay wenn man sich dann schon anstecktdann möglichst früh so bevor alles zusammenbricht so aber nein natürlich will man nach möglichkeit sich nicht anstecken sondern die zeit bis es einen impfstoff.Wirklich ja.
Tim Pritlove 0:54:10
Oder zumindest der medikamentöse behandlung.
Pavel Mayer 0:54:13
Ja wobei bei medikamentösen behandlungen auch wenn wir jetzt bei den zahlen gerade sind ist es so.Die antiviralen medikamente so die funktionieren am besten wenn sie in einem sehr frühen stadium gegeben werden da aber der verlaufbei einer großen zahl der leute eher nicht so schlimm ist ist es jetzt nicht gerechtfertigt.Sagen weil die auch alle experimentell sind und nicht zugelassen sind leuten die.Leichte oder keine symptome haben diese unangetastet hammer medikamente da muss man auch sagen dass sie teilweise damit die auch wirken in extrem hohen dosen gegeben werden müssen und wirklich nebenwirkungen haben.
Tim Pritlove 0:54:56
Das will man jetzt nicht haben aber ich habe ja jetzt auch von einem einer theoretischen das kann ja auch sein dass.Mit einer therapie medikamenten geschützt oder nicht daher kommt die dann sozusagen den krankheitsverlauf auch in späteren fällen nochmal das ist nicht da ja aber auch.Ist ja auch nicht da.
Pavel Mayer 0:55:17
Jaalso am ende des des tages würde ich sagen wird es also ja wird selbst wenn's medikamente gibt ist so die hoffnung dass man sie dann in schweren fällen oder vielleicht bei risikopatienten einsetzen kann aber wenn man jetzt auch gucktwie das bei anderenviralen erkrankungen ist beim großteil von von denen ist man da auch zurückhaltend mit jetzt antiviralen medikamenten weildie halt so ja sie funktionieren aber das.Erfordert lange lange forschung und so also meinich persönlich habe ich jetzt nicht das große vertrauen in eine medikamentöse therapie das dass die aber es lindert natürlich alles das hilft natürlich alles aber.Eigentlich brauchen wir eine eine impfung so da kommen wir da hat man natürlich auch wieder das problem normalerweise so als zwei drei jahre bis man einen impfstoff hat wo man sicher ist dass wenn man jetzt eine million leute impftdenn nicht achthunderttausend mit ihm schäden.Oder wenn man selbst bei also wenn man jetzt die gesamte bundesförderung durchkämpfen will will man den impfstoff haben der einfach extrem sicher sind weil selbst wenn nur jeder tausendste oder jeder zehntausendstenjetzt schäden davon trägt sind das halt auchsignifikante zahlen von leuten und und dann betrifft es halt auch ja dann ist die frage gut wen impft man dannegal wir waren bei den zahlen vielleicht nochmal zurück jetzt zu den zu den zahlen.Zum vergleich dazu sagen was was ich mache mit den zahlen ist eben logistische kurven.Zu finden also ich rechne einfach eine funktion die eben bisher erstaunlich gut aufalle verläufe die ich gesehen habe passt das heißt nicht dass es passen muss so auf alle verläufe aber es ist wirklich verdammt gut unddas schöne ist dass man dann an diese funktion dann mit analytischen mitteln rangehen kann also man kann dann halt die nochmal relativ einfachleiten und kann dann gucken wo es sind die wendepunkte wo es die größte krümmung die größte steigerung die kleinste krümmung so sprich.Wenn man sich die kurve anguckt kann man viel genauer als jetzt in den diskreten zahlen sagen okwie wie weit liegt jetzt der wendepunkt sprich also wo wir von einemexponentiellem wachstum dann geht's irgendwann ins lineare über und dann eben letztlich in der logarithmus wachstum über sie kurve schwächt dann wieder ab und.Bei uns.Es ist jetzt so in in deutschland dass so mit den mit den aktuellen daten von heute das so aussieht als wenn der wendepunkt zwei drei vier fünf.Fünf tage zurück liegt jetzt sozusagen.Wir vor fünf tagen der punkt des höchsten absoluten anstieg war und.Wir jetzt gerade ja sind wir kurz vor dem punkt.Der höchsten krümmung also in den nächsten tagen müsste es noch am stärksten zurückgehen in den nächsten ein zwei tagen nach meiner kurve die ich habe die.Im moment einen endstand bei also am wahrscheinlichsten bei knapp.Achtzigtausend also eigentlich sogar nur fünfundsiebzigtausend in der in der spitze angibt mit fehler zwischen fünfundsechzig bis neunzigtausend wobeiich die fehler berechnung auf andere art und weise mache ich berechne halt dann den nächsten tagrechne dann einen fehler in den wert vom nächsten tag ein um zwei standardabweichungen aus der bis bisherigen kurve also je nachdem wie unregelmäßig die datenwaren sage ich mal istauch erhöht sich dann die die die standardabweichungen und dementsprechend vergrößere ich den fehler und gucke wenn die halt um zwei standardabweichungen nach oben und zwei standardabweichungen nach unten macht da eine neue kurve undmacht das dann so für den nächsten tag auch für die nächsten fünf tage und dann lasse ich die funktion aber weiterlaufen und.Interessanterweise sieht es halt recht gut aus und die liegen auch selbst mit diesen fehler von zwei standardabweichungen gar nicht mehr so weit auseinander und meine vorhersage für in fünf tagen,liegt so bei.Würde ich sagen mit einem fehler zwischen siebzigtausend undachtzig.Also mein mein fehler range gerade für für meine fünf tages prognose oder wenn ich das jetzt sechs tage das wären dann ja zwischen vierundachtzigvierundsiebzig bis vierundachtzig tausend die.Andere sache noch ist was was man sagen kann das zu unterschiedlichenzeiten unterschiedliche arten von vorhersagen gemacht werden können was man haltimmer machen kann auch schon sehr früh ist sozusagen eine best case vorhersage wenn wir jetzt alles tun um das zu reduzieren wo können wir die kurve dann noch zum stoppen,verbringen so das kann man immer sagen das heißt dann die untergrenzen sind relativ klar weil ich natürlich nicht in der summe nicht weniger fälle kriegen kann als ich jetzt schon habe das heißt ich kann dieses vollbremsung szenario kann ich halt als untergrenze schon malermitteln und.Kann dann auch gucken okay wenn ich ein bisschen weiter fortgeschritten bin ist denn irgendwie eine leichte brems verzögerung schon zu spürenin den daten und wenn ich diese leichte brems verzögerung schon spüre kann ich halt versuchen diese bremse zögern eben auch vorherzusagen dass jetzt wie stark ist jetzt die eingeleitetebremsung und wenn die jetzt weiter anhält was was passiert dann das ist im prinzip wie man auf die daten kommtnach obenist es natürlich immer offen es kann auch immer irgendwas passieren dass plötzlich wieder eine neue ausbruch da ist oder dass eine motivation gibt oder weiß ich nicht so das heißt die obergrenzen sind immer ein bisschenweniger sicher.
Tim Pritlove 1:02:35
Also wenn ich das richtig raushöre meintest fünf tage zurück hat sich was abgezeichnet so.Der der eigentliche lok down ist jetzt stand heute ungefähr seit zwei wochen so richtig aktiv also vor fünfzehn tagen um die schulen zugemacht in berlin ein paar bundesländern ging es ja schon ein bisschen früher los schon am wochenende davor und dann hat's natürlich auch noch eine weile gedauert bis ich das sozusagen in der gesellschaft auch alles ein bisscheneingehängt hat nicht jeder hat sofort alle aktivitäten aufgegeben etcetera pund wenn sich jetzt sozusagen vor fünf tagen jetzt schon was zeigt in die daten was jetzt noch nicht sicher ist wenn man gleich dazu sagen aber dann würde das ja sozusagen auch.Einen einblick geben dass so nach acht neun tagen das eben auch schon eine auswirkung hatte so in der größenordnung bisschen mehr als eine woche.
Pavel Mayer 1:03:30
Also ja es ist es es spricht lang einiges dafür dass man sagen auch schonbevor die harten maßnahmen getroffen wurden es einfluss gegeben hat wobei ich sagen muss die melde dauer von den zahlen ist soja im besten fall neun tage nach erkrankungaber kann bis zu vierzehn tage dauern also zehn tage waren eigentlich bevor es halt so richtig los ging.So hatte ich zwei fälle weiß ich von zwei fällen wo es also von einem fall wo es zehn tage ungefähr gedauert hat in einem anderen fall zwölf tageauf der anderen seite ist es so dass es aber natürlich auch fälle gibt wo es schneller geht wo die leute ganz schnell erkranken und ganz schnell ins krankenhaus gehen und der test ganz schnellda ist sodass man wenn es davon viele gibt kann man eben tatsächlich schon erste effekte nachhaltig sieben.Tagen oder so sind sind durchaus möglich dass sie nach sieben acht tagen und das scheint jetzt auch tatsächlich der fall zu sein und ich muss sagen nach dem heutigendaten punkt bin ich mir auch mittlerweile sehr sehr sicher dass sich da was tutin denzahlen so also gestern war ich noch ein bisschen vorsichtig weil die daten vom wochenende ist halt immer so dass wir halt am wochenende mal einen einbruch hatten bei den daten weil haltes zu melde verzögerungen gekommen ist so das heißt wir hatten immer ja samstag sonntag war immer weniger das hatten wir.Diesen dieses wochenende auch aber zum einen in einem geringeren ausmaß als das wochenende davor undes scheint aber so zu sein dass diese rückgänge auch real sind das einzige was ich mir vorstellen kann was die zahlen so verzerren könnte.Wäre wenn den testlabor aus irgendwelchen gründen test materialien ausgehen und die zahl der tests runtergefahren worden wäre dafür gibt's aber.Keinerlei anhaltspunkte derzeit und trotzdem sind die zahlen runtergegangen und befinden sich jetzt auch.Sagen wenn man das hochrechnet anhand der zahl der der der infizierten scheinen wir uns auch in dem bereich zu befinden.Das obwohl wir jetzt obwohl nicht alle getestet werden dass dass wir nicht an den grenzen der test kapazitätliegen was jetzt diese aktuellen rückgänge angeht sondern die scheinen tatsächlich echt zu sein und natürlich merken das müssten es als erstes auch die gesundheitsämtern.Merken viel früher so fünf tage früher sie müssten dann halt auch merken und die krankenhäuser auchhat sich da was getan bei der zahl der leute die bei uns vorstellig werden und da gibt es sagen auch.Meldungen dass die gesundheitsämtern auch das gefühl haben es entspannt sich etwas aber das ist natürlichschön wär's wenn man halt zahlen zahlen hätte wie viel anträge sind denn eingegangen oder wie viele leute jaaber nichtsdestotrotz ich bin halt dort zuversichtlich.
Tim Pritlove 1:06:57
Milde optimistisch.
Pavel Mayer 1:06:59
Ich bin halt ich würde sagen sogar sehr optimistisch dass sich was tut das sagen wir jetzt das was das wir in den zahlen jetzt bereits die auswirkungen der maßnahmen sehen können und.Meine.Vorhersage oder meine hoffnung auch ist dass ich das jetzt in den nächsten tagen nochmal deutlich stärker bemerkbar machen wird zumindest bei der zahl der infizierten bei der zahl der toten.Laufen wir halt leider etwas hinterher also die kommen halt später da werden wir es wahrscheinlicherst in zehn tagen oder so in ein bis zwei wochen werden wir dort leider erst den höhepunkterreicht haben wobei ich komischerweise.Das ergebnis gekriegt habe also numerisch dass halt die zahl der der totender zahl der infizierten gar nicht so weit hinterher läuft sondern nur zwei so eher größenordnungsmäßigen drei tage wo es noch nicht ganz pasta wie auch immer.Würde man sagen okay wir werden wahrscheinlich den höhepunkt bei den täglichen toten in frühestens drei tagen javielleicht haben wir ihn heute schon erreicht aber wir.Wenn wir pech haben erst in ein zwei wochen also da kann man noch keine hoffnung schöpfen und auch aus der kurve aus dieser zahl heraus da ist bei der zahl der toten noch keine abflachungsichtbar im moment.
Tim Pritlove 1:08:38
Dann lass uns doch mal einen kurzen blick auf den rest der welt wagen.Bevor wir dann vielleicht abschließend auch nochmal drüber reden sollten was so noch alles auf uns zukommt.Italien war vor zwei wochen schon der hotspot da hat sich im prinzip alles erst so richtig entfacht.Mittlerweile ist spanien dazugekommen.Und es sieht überhaupt nicht gut aus in den usa und meiner meinung nach auch nicht besonders gut aus für das vereinigte königreich.Was so deine wahrnehmung wie das in anderen bereichen der welt so läuft derzeit.
Pavel Mayer 1:09:24
Ja also zu italien deckt sich meine vorhersage im moment mit der erotikvorhersage also mein modell ist da nicht grundsätzlich optimistischer sondern nur für deutschland im moment für italien liegtungefähr gleich italien befindet sich gerade in einer sehr sehr langen sagen.Linearen phase die sind auch aus dem exponentiellen raus aber der knick ist da zwar schon merkbar aberes wird wohl noch eine ganze weile noch nach oben gehen und ich habe jetzt die datenpunkte der letzten beiden tage noch nicht drindie letzte vorhersage für italien habe ich gemacht eben vor zwei tagen und da läuft es im moment aufhundertfünfundfünfzigtausend läuft es bei mir raus wo das dann zum halt kommen könnte das heißt italien.Hat noch so ein drittel der infektion noch vor sich ungefähr.Obwohl es dort bereits runtergegangen ist bei uns sieht es dagegen so aus als wenn wir härter auf der bremse stehen sage ich mal aber sagt wie hart das.Da werden noch ein zwei drei tage bräuchten wir noch um dass ich das hinreichend bewahrheitet aber das ist sozusagen der unterschied zwischen deutschland und italienansonsten bei den amerikanischen zahlen die habe ich auch mal reingeworfen und der exponenten beginnt ziemlich früh zurückzugehen aber so dortkann man zur obergrenze nicht viel sagen also da wo es wo es hin läuft also die sind nochirgendwie gerade voll in der krasseneinstiegsphase im moment also usa lohnt lohn sich vorhersagen fast kaum da ist im moment den reinen zahlen nach erstmal noch echt apokalypse angesagt.
Tim Pritlove 1:11:30
Ja vor allem ist ja auch die reaktion in den usa überhaupt nicht homogen also florida laufen sie immer noch alle rum und hängen an stränden rumkeine ahnung wie das jetzt konkret heute gerade in diesem moment aussieht et cetera maxi speak schon geändert haben aber es war sozusagen nicht so dass jetzt alle gesagt haben okay zack usa runterfahren fertig sondern das ist halt hochgradig abhängig vondem jeweiligen government von jeweiligen als staaten.
Pavel Mayer 1:11:58
Ähm.Ja ja also die machen die sind halt irgendwie ein bisschen später dran mit den langen reaktionen oder wenn der die sind in der panik kurveoder in derkurve wo politiker handeln einmal deutlich hinterher und das recht sich halt natürlich gerade wobeidie amerikaner auch nicht unterschätzen sollte also die haben halt in einer woche von zehntausend auf fast hunderttausend tests pro tag hochgefahren jada haben wir deutlich sind wir.Kann das eher gemächlicher auf gebaut wobei du natürlich die kapazitäten nicht hochfährstwenn keine proben da sind also bringt nichts jetzt kapazitäten für hunderttausend zu haben wenn du nur tausend probenkriegst aber du willst natürlich das schon eigentlich so früh hochfahren dass dass du genug tests halt anbieten kannst und,bei uns hätte es ein bisschenschneller gehen können wobei wir bei auch schon auf einen ziemlich hohen niveau gestartet sind muss man auch sagen also da sind nur ich glaube eigentlich fast nur die norweger sind da besser und ein paar andere norweger.Glaube ich auch zweieinhalbmal so viel geld ihr in ihr gesundheitssystem wie wir.Ja und dann gut andere länder also tschechien sieht.Jetzt eigentlich die tschechen waren halt relativ frühdran muss manmuss man sagen mit mit maßnahmen und die haben halt was was sie halt gemacht haben war sehr schnell zu sagen okaykeiner geht mir heraus ohne maske so das war halt sagen sehr sehr früh dortohnebei uns hat man gesagt naja aber wir haben keine masken und wenn dann die leute anfangen masken zu tragen dann haben die ärzte irgendwie keine masken und so die tschechien haben halt einfach gesagt maske oder bleibt zu hause und das führte dann dazudass die leute sich halt alle masken genäht haben und ihr habtauch noch verwandte da meine cousine hatte schon angeboten in den kernpaket zu schicken die hat ja ein paar bilder geschickt die ich auch getwittert hatte mit ihren produktion und die haben gerade spaß alsojeder jeder zweite sitzt halt an der nähmaschine und hat halt spaß beim masken nähen weil halt sonst nicht nicht viel los ist und und es dauerte wohlirgendwie nachdem das die region gesagt hatte nur nur noch raus mit maske dauerte es zwei tage und alle leute hatten irgendwie masken.So
Tim Pritlove 1:14:43
Sie an auf einmal geht das.
Pavel Mayer 1:14:45
Und ich weiß von leuten so die einfach die sogar einfach unterhosen genommen haben und sich einfach umgebunden haben.Oder andere dinge.
Tim Pritlove 1:14:55
Wunderbar geht das sogar ne also ich habe mir auch eine maske genäht mittlerweile und hatte da auch eine ganze menge spaß dabei weil man macht das ja auch nicht alle tage dass man sich jetzt mal so custom irgendwas näht ich bin jetzt nicht so der typ der seine eigene kleidungmacht aber so ein kleines überschaubares funktionsprinzip ist schon ganz gut.Denke was passt was wir mit mit zwang und druck hier nicht gelöst bekommen das kriegen wir zumindest in berlin mit fashion hin also es muss.
Tim Pritlove 1:15:24
Cool werden und dann dann dann geht das auch ratzefatze.
Pavel Mayer 1:15:30
So also wie gesagt in in tschechien irgendwann die tschechen sind historisch irgendwie weiß nicht was krankheiten angeht sind die halt schon immer ziemlichkrass gewesen so bei der epidemie ein eindämmung also die haben da auch immer eine gesetzgebung gut die haben wir im prinzip auch aber sie wird halt nur nicht.Tschechien hat ich hatte das erwartet also bevor das losging dass die wahrscheinlich sehr früh sehr drastisch rangehen werden was nicht nur an der regierung liegt sondern weil das dort halt jasagt krankheiten da kennt man da irgendwie keinen spaß so da wird.Lieber gleich draufgehauen und so haben die das halt auch gemacht plus was sie halt auch gemacht haben was auch eine interessante,art war dass sie gesagt haben dass sie bestimmte zeiten am tag reserviert haben in supermärkten für risikogruppen das heißt zwei stunden ich glaube von zehn bis zwölf oder sodürfen halt nur ältere menschen.Dort in supermärkten einkaufen damit man da sagen zusätzlich noch 'ne entkoppelung hinbekommt keine ahnung wie viel das hilft aber fakt ist dass tschechien und da muss mannoch sehen dass sich ja einen großteil der bevölkerung.Ziemlich großer teil halt in einer einzigen stadt dort tummelt oder in zwei städten wo natürlich dasdie verbreitung tendenziell auch noch schneller vonstatten gehen kann und da sieht es aber ganz,gut aus sie liegen im moment nach letzten zahlen irgendwo bei dreitausendfällen das ist so eine institut ganz so weniger als die hälfte pro kopf so würde ich sagen zwischen der hälfte und einem drittel der menschen sind dort.Infiziert pro kopf wie in deutschland und es sieht auch so aus dassdie ersten maßnahmen dort jetzt zugreifen beginnen auch da kann man so eine kann man schon eine deutliche abflachung der kurve sehen.
Tim Pritlove 1:17:47
Kommen wir doch nochmal vielleicht als nachtrag zu der ganzen zahlen spielerei.Dazu welche zahlen jetzt sozusagen künftig noch interessant werden können also wir werden ja jetzt mit großer wahrscheinlichkeit demnächst auch neue tests bekommen tests auf immunität.Die werden sicherlich den modellen auch nochmal ganz interessantes futter geben beziehungsweise auch ganz andere fragestellungen beantworten können nämlich.Auch so die frage mit wie viele leute waren denn jetzt vielleicht wirklich infiziert weil wenn man halt im großen stil mit einfachen tests immunität nachweisen kann alsoantikörper tests sind ja im gespräch ja die relativ leicht selbst durchgeführt werden können.Oder zumindest in größeren stil von personal durchgeführt werden können so dass man eben feststellen kann so aha okay du hast vielleicht nie was gemerkt.Oder du hast nur leichte symptome die du so gar nicht jetzt einer potenziellen corvette erkrankung zugeschrieben hast aberwir haben halt mal reingeguckt und in dir schwimmt halt die entsprechende antikörper materie rum du wirst es mal gehabt haben und nach unserem aktuellen.Wissensstand der nicht gesichert ist aber der nun mal der aktuelle wissensstand ist es sieht halt so aus als ob im wesentlichen immunität.Stattfindet also wenn man's gehabt hat und man hat's überlebt dann.Und man hat auch keine bleibenden schäden von der harten erkrankung bekommen dann ist alles gut sozusagen das zumindest der aktuelle blick es gibt ein paar verstörende berichten immer wieder aus china wo's gruppen gibt die.Irgendwie nochmal positiv getestet worden sind aber ich glaube das ist noch nicht in dem maße erhärtet dass man sagen kann okay da weiß man wie vorher getestet wurde et cetera muss man abwarten aberdas ist jetzt zumindest erstmal die perspektive die sich jetzt bietet muss man da jetzt komplett neue zahlen modelle aufmachen um das sozusagen noch mit einzurechnen oder fügt sich das wunderbar.In das bestehende bild und man hat einen glücklichen neuen parameter.
Pavel Mayer 1:19:55
Ja man kann natürlich dann dann deutlich viel mehr machen und es gibt auch irgendwie ein trosten podcast wo er genau zu dem thema jetzteiniges sagt und da ist wohl so dass es die tests an die körper schon gibt und dass die labore also in deutschlandjetzt gerade dabei sind die kapazitäten hochzufahren also der test ist schon validiert und mit stempel vom und so dass da funktioniert und man weiß wie's geht und die bloßdie kapazitäten sind noch nicht da aber die werden wohl da kann man wohl in eins zwei drei wochen wird's halt genug labor kapazitätfür die labor antikörper tests geben und dannwo es dann nochmal einfacher wird ist wenn es dann tests mit sogenannten lateral flow die weißes gibt also im prinzip schwangerschaft-test wo man dannauch über einfach wie eine wie blutzucker tests sich halt mit einem pixel ein bisschen blut aufauf so einem test gibt und dann nach fünfzehn zwanzig minuten oder so sieht man dann irgendwelche striche und kann dann sagen es positiv oder negativ da gibt es wohl auchweniger von diesen aber im moment nicht validiert und die gibt's auch nicht hin in deutschland sind aber werden aber gerade wohl wohl auch getestet das zu den tests so.Und zu der frage okay wie geht's jetzt weiter mit den vorhersagen mich hatte vor allem erstmal interessiert wie gehtdie entwicklung weiter bis zur ersten eindämmung sag ich mal weil was relativ schnell klar war okay was immer klar ist keine epidemie.Läuft für immer so es gibt irgendwann eine maximale zahl von infizierten wo es zum halten kommen wenn ihr mich alleerkrankt sind und durchimmunisiert ach ja und zur immunisierung ist es wohl sogar so sagt jedenfalls trotzdem erste studien darauf hindeuten dass wir sogar 'ne sehr gute immunität entwickeln gegen sehr früh sehr schnell das im prinzip der körper nachzwölf stunden schon beginnt mit antikörper bildung und.Ja also das ist scheint sogar so zu sein dass es sich bei diesem virus ein handelt der eigentlich.Für das immunsystem normalerweise also der sehr sehr gut erkannt wird vom immunsystem sehr früh erkannt wird und auch von dem angeborenen immunsystem sagen schon bereits angegangen wird.Was halt ganz gut ist insofern also was ich da gehört habe was aus studienziel wurde brauchen wir uns was das thema immunitätangeht jetzt keine großen sorgen zu machen dass das da noch überraschung geben könnte wie gesagt im moment das aktuelle interesse wann flacht die kurve ab wannerreichen wir erstmal einen plateau so aber die offene frage ist wie sie dieses plateau aus in china.Kann man ein bisschen sehen china meldet pro tag ungefähr hundert neu infizierte seit einer ganzen weile auch mit langsam rückgang aber extrem langsam das heißtda kocht das quasi jetzt auf ganz kleiner flamme im moment in china aber es köchelt noch vor sich hin.Und dort beginnt man jetzt die restriktion wieder runterzufahren und da wird's natürlich interessant sein zu sehen gehtdas ganze wieder hoch weil bei hundert neue erkrankten weiß man okay gibt's noch eine dunkelziffer und und so aber da sitzt die krankheit quasi schon in den startlöchern in dem moment wenn man jetzt sagen würde okay wir gehen jetzt wieder zurück auf anfang wir wir wir.Wir machen jetzt weiter wie wie wie vorherdann ist man sofort wieder in dem exponentiellem wachstum drin und dann kann man sagen gleich nach ein paar wochenwieder den nächsten shutdown machen weil es droht aus der hand zu laufen so wird es natürlich nicht laufen sondern wird jetzt.Dann gucken erstmal einzelne maßnahmen von denen man glaubt dass sie jetzt nicht soschlimm sind aber wichtig sind dass man halt wieder mehr sagen firmen erlaubt dinge zu tun schulen stehen auchganz ist auch ganz hoch die frage nach sagen wann können wir halt wieder die schulen eigentlich aufmachen dass das wird viel.Debattiert gerade weil eigentlich kinder jetzt nicht so sagen in in der regel nicht so schwer von der krankheit.Betroffen sind so dass man sagt okaywir testen jetzt mal an unseren kindern das ganze wobei ja da natürlich auch stimmen sagen ok aber die die kinder und jugendlichen haben da vielleicht auch noch ein wort mitzureden ob sie jetzt sozusagen unsere test kohorte sein wollen zur zur ausbreitung also das wird auf jeden fall noch.Krasse debatten geben meine cambridge studie hat da auch verschiedene unschöne szenarien.Gemalt nämlich wenn wir das wir sagen von von shutdown zu shutdown eilen sagen dann die maßnahmen aufheben dannein paar wochen sagen wieder alles offen ist und man dann wieder runter fährt und das sofür die nächsten zwei bis drei jahre und selbst dann hätte man aber noch nicht sagen genügend immunität in der in der bevölkerung sodas wichtigste jetzt also für zukünftige.Prognosen wäre es natürlich rauszufinden wie stark wirkt sich eigentlich eine maßnahme auf die ausbreitung des virusso dass es das wären die wichtigsten informationen die jetzt politische entscheidungsträger brauchen also was passiertwahrscheinlich wenn wir die schulen aufmachen welche schulen machen wir auf wie machen wir sie auf also machen wir was dass ich nur jeden zweiten jahrgang auf erstmal oder.Abwechselnd also da gibt's halt ganz ganz ganz ganz viele variationen und da ist es natürlichbedauerlich gerade dass halt diese ganze.Melde kette nicht so optimal ist wie sie ist weil also wir hatten natürlich über die wirtschaftlichen auswirkungen wollten wir eigentlich auch reden aber wir sind jetzt schon viel länger zugange als wir eigentlich vorhatten.Aber grob übernommen so.Ein berg am tag so also ja um die größenordnung fünf also vier bis sieben milliarden ungefähr jetzt kostet uns oder gut kosten ist die frage wir müssen's ja doch.Also es fehlt uns im brutto inlandsprodukt auf jeden fall und geht davon aus dass das bruttoinlandsprodukt sagen während des shutdown um rund die hälftesinkt auf jedenfalls in den ersten wochen wenn man jetzt länger und öfter shutdownmacht dann in späteren shutdown kann man das wohl auf fünfzehn bis fünfundzwanzig prozent reduzieren aber sagen jetzt der erste shutdown der geht so richtiggerade ins geld und berlin hat jetzt wohl was die ersten dreieinhalb millionen an soforthilfen für selbstständige überwiesen.Ja ich bin jetzt selber noch nicht in die warteschlange reingegangen weil ich mir mal denke ich weiß nicht ich muss mich irgendwie nicht immer als als allererster anstellen aber eigentlich hätte hätte man vielleicht tun sollen weil das sind tatsächlich wohl zuschüsse die da gerade ausgezahlt werden und ja.Also ich werde mir das halt denn jetzt nach dem nach dem podcast hatte ich eigentlich mal vorbei als ich dann mir überlegt hatte okich gehe mal jetzt drauf hieß es okay welt website überlastet geht jetzt gerade nicht so ist jetzt webseite hatist es geschlossen und komm bitte morgen wieder und ich glaube das ist auch noch der der zustand ich glaube ich kann da erst frühestens irgendwie morgen wieder.
Tim Pritlove 1:28:12
Dreiundzwanzig uhr macht sie zu.
Pavel Mayer 1:28:15
Ok gut dann ja.
Tim Pritlove 1:28:18
Bis sechs uhr du musst schlafen weißt du dass es wichtig dass so ein computer muss schlafen.
Pavel Mayer 1:28:23
Aber ich glaube man fliegt auch aus der warteschlange raus irgendwie wenn man also ich bin mir nicht sicher ob man am nächsten.
Tim Pritlove 1:28:30
Also es gibt da sehr unterschiedliche berichte und das mag sich jetzt auch am laufenden meter erinnern alsoalso wie auch immer es ist auf jeden fall auch eine herausforderung dass leute ein formular ausfüllen zwanzig zwanzig im internet das nehmen wir jetzt einfach mal soso zur kenntnis hätte ja keiner mit rechnen können vielleicht mal so zum abschluss jetzt dass man mal die ganzen zahlen und modelle mal ein bisschen außen vor undohne dass jetzt auch zu tief vertiefen zu wollen aber.Wir werden ja jetzt so oder so in irgendeiner form mit wie viel verlusten und schmerzen auch immer an so einem punkt kommen wo erstmal die situation.So ist das eben dieser unkontrollierte ausbruch der halt droht das gesundheitssystem zu belasten irgendwie in griff.Kommt ne also denn den punkt werden wir früher oder später erreichen meine frage dazu ist was dann.Weil das ist ja jetzt sozusagen du hast ja schon angedeutet so der nächste schritt dauern kommt bestimmt und.Ich glaube so ein shutdown wie wir ihn jetzt hatten in der form in der dimension soll natürlich so verhindert werden jetzt muss man sich sozusagen darüber gedanken machen wie man dann eben die sache unter kontrolle hält.
Pavel Mayer 1:29:48
Also meine vermutung ist dass das ganze thema masken die werden uns 'ne ganze weile erhaltenbleiben ich rechne damit dass ja in der öffentlichkeit man sehr lange leute mit masken sehen wird also es lohnt sich immer noch sich eine zu nähen glaube ich oder mehrere.Sehr wahrscheinlich wenn sich das erstmal wenn bei uns erstmal sich das durchgesetzt hat dasman nicht wie ein verrückter angeguckt wird wenn man mit maske unterwegs sind ich weiß von leuten die das ganz früh schon gemacht haben und die wurden teilweise sogar aggressiv angegangen deswegen wareine maske getragen haben das kehrt sich glaube ich jetzt auch um aber so das ist sicherlich.Das dass das eine ding was passieren wird soich sehe ziemlich schwarz für großveranstaltungen also fußballtor muss ich es weil ich habe das.Halt mal sondern wenn man halt durchgerechnet sagen wie groß ist das risikoauf einer veranstaltung sich anzustecken so da gibt's natürlich die.Wie viel infizierte gibt es in der bevölkerung wie wahrscheinlich ist es dass jemand irgendwie dort mit dabei ist je kleiner die veranstaltung umso wahrscheinlicher dass kein infizierten dabei ist so und,natürlich dann die frage okay wenn einer jetzt dabei ist oder ein.Infektiöse sagen wir mal so wie viel schaden kann der dort dort anrichten und bei fußballstadien vielleicht haben wir sowas erleben.Dass es dann spiele geben wird wo dann jeder zweite sitzplatz oder jeder dritte nur.Besetzt ist also und stehplätze gar nicht so dass man halt dann zwar spielt aber nur vor kleinen publikum an der interessante grundwarum spiele so schnell abgesagt worden war ja wohl nicht die gefahr für die öffentlichkeit sondern weil man ganz viele infizierte spieler hattealso in verschiedenen mannschaften und die spieler dann gesagt haben ey leute haben keine lust mit anderen infizierten jetzt fußball zusammenzuspielen.
Tim Pritlove 1:32:01
Ja das also das war sagen wir mal das war dann die letzte nagel im sarg ne also primär ist natürlich schon das problem im publikum zu sehen und das andere problem war dann.Natürlich auch sagen wir mal die spieler an sich aber eben einfach die tatsache dass wir eben ein spieler entsprechend positiv.Indiziert ist dass dann natürlich im zweifelsfall auch denkt die ganze mannschaft in quarantäne gehen mussten dann natürlich nicht dauernd dran zu denken dass man einen normalen spiel.Betrieb durchführen kann wenn dann einfach mal so hops von heute auf morgen eine ganze mannschaft ja nee wir sind dann mal zwei wochen nicht dabei also das funktioniert halt auch hinten und vorne nicht.
Pavel Mayer 1:32:37
Und leider natürlich dann auch.Konzerte das ist finde ich ziemlich bitter dass das wahrscheinlich jetzt eine ganze weile vergehen wird so bis wir wieder mitzigtausend anderen leuten irgendeiner band lauschen können weil ich mir nicht vorstellen kann dass man dort.Bock hat das dann gut wir werden sehen vielleicht gibt's da dann auch neue kulturelle ideen wie man wie man das macht aber wie man irgendwie social distanz auf einem rock-konzert machen kanndas sehe ich jetzt gerade noch nicht das ist natürlich ziemlich bitter konferenzen wird's wahrscheinlich auch langenicht nicht geben so weil man da.Wiederum sagt okay wir machen das dann dann lieber remote und so da die notwendigkeit nicht besteht.
Tim Pritlove 1:33:36
Wir haben auch schon einige leute festgestellt dass das ja irgendwie eigentlich gar nicht so doof istund man wirklich zum kern austausch der informationen ja irgendwie dann doch nicht irgendwie nach bulgarien fahren muss und sich ein hotel mieten muss und die.Kosten hat und die übernachtung.Und überhaupt die ganze zeit und nichts anderes tun kann als das in dem moment et cetera also ich denke videokonferenz an sich und diese ganze täler arbeit ist der große gewinner in anführungsstrichen dieser ganzen situation dass.Sehr viel dort hängen bleiben wird weil jetzt einfach mal alle einmal das durchexerziert mussten viele werden auch festgestellt haben okay das ist eigentlich nicht das was ich haben will es gibt.Gerade nichts anderes aber sehr viele bereiche werden halt auch feststellen so okay alles klar man kann konzern auch fahren wenn irgendwie alle mitarbeiter zu hause sind oder zumindest ein großteil.Ja da können wir uns dann aber auch eine ganze menge büro platz.Fahrtkosten etcetera pendler aufwand und so weiter sparen und vielleicht ist das sozusagen auch ein modell mit dem dann unsere firmenkultur auch klarkommt.
Pavel Mayer 1:34:45
Das habe ich auch gedacht dass es wahrscheinlich dann in zukunft deutlich mehr leute gibt die remote arbeiten oder sich in videokonferenzen treffen oder wie auch immer und und es ist ja auch also ich mache das.Auch schon jetzt seit seit längerer zeit also ungefähr ich sag mal die hälfte meiner arbeit oder oder treffen läuftremote weil ich halt für verschiedene firmen teilweise im ausland arbeite oder mitarbeiter in anderen städtengesessen haben oder so und irgendwann vergisst man halt komplett sagen dass es sich dass man in einer videokonferenz ist gerade wenn man nur mit einem einer person oder so dann zusammenda arbeitet ist es dann fast so als wenn die derjenige neben einem sitz so man.Zusammen am rechner und quatscht halt einfach und ja als wenn die person neben einem wäre das finde ich funktioniert ganz gut arbeiter noch ja reisen also tourismusist natürlich dass das wirklich bittere thema zehn prozent ungefähr des des weltdes bruttoinlandsprodukts der welt sind alleine tourismus in vielen ländern noch mehr in großbritannien sind es genau die zehn prozent in deutschland ungefähr acht prozent und das ist natürlich für dieses.Gewaltiger wirtschaftsfaktor ist wenn man sich überlegt allein auch jetzt für berlin wie viele hotels und wie viele menschen da drin arbeiten wie sich dasdann weiterentwickeln soll oder wird also da wird es sicherlich also bis ich das normalisiert kann man wahrscheinlich.Zwei drei vier jahre eher rechnen also auf jeden fall müssen wir da komplett durch sein selbst dann werden vielleicht noch entwicklung bleiben dann.Natürlich luftfahrt luftfahrtim moment sind irgendwie neunzig prozent der flugzeuge am boden fast fünfundneunzig prozent das natürlich riesige probleme in sich.Aufwirft so weilpiloten müssen fliegen damit sie ihre zulassung behalten die brauchen pro quartal nur mindestzahl an flugstunden machen aber teilweise flughäfen zu und so das heißt die laufen da auf einen einen riesen problem rein.Boing hat wenigstens jetzt nicht das problem jetzt mit denen die sieben drei sieben flotte so schnell.Ans fliegen also die drei sieben max als fliegen zu bringen da wird jetzt gerade nicht mehr nicht viel drüber geredet weil ja ja dann sehr traurigim moment ist kein a drei drei achtzig airbus a dreihundertachtzig mehr in der luft alle weltweit sind gegründet und niemand weiß ob sie jemals wieder fliegen werden.
Tim Pritlove 1:37:30
Da gibt's auch schon einschätzung dass das dass das vielleicht schon gewesen sein könnte weil die ohnehin vom markt abgezogen worden aber das natürlich insbesondere diese extremen fernreisen jetzt nochmal ein extra malus bekommen.
Pavel Mayer 1:37:42
Sehr sehr bitter dann kommt noch dazu wenn ein flugzeug längere zeit steht da kannst du nicht einfach wieder damit fliegen sondern dann dann sind halterhöhte checks erforderlich genauso wie bei den piloten wenn die längere zeit nicht fliegen müssen die halt im simulator erstmal sonst für simulator stunden machen beim flieger wenn der länger nicht fliegt ist halt eine eineviel aufwendiger check-in notwendig.Positiv wir könnten wahrscheinlich in diesem jahr in deutschland die klimaziele erreichen so die gesetzten was sonst.Weiß nicht seit jahrzehnten nicht nicht gelungen ist.
Tim Pritlove 1:38:23
Auch die luftverschmutzung in den städten ist enorm zurückgegangen.
Pavel Mayer 1:38:30
Also positive umweltausschuss wirkung hat das sicherlich auchwobei wenn man jetzt diese menge an geld wenn man da jetzt nur überlegt wenn man die eingesetzt hätte sagen.Gut idealerweise natürlich zur pandemien vorsorge und abwehr aber gutshit happens ich meine in den usa aber jetzt noch eine eine geschichte lesen kalifat kalifornien unter schwarzenegger schwarzenegger hatte nach saß.Damals irgendwie dreihundert millionen locker gemacht um notebook widmet für kalifornien für den epidemie fallanzuschaffen also komplette.Krankenhäuser und beatmungsgeräte und alles was man so braucht um eine signifikante zahl an menschen behandeln zu können also.Krankenhäuser in der boxmit luftfilter aktionsanlage mit schutzausrüstung und masken und alles was halt jetzt total geil wäre das zu haben aber so der nachfolgerhat halt angesichts der finanzkrise dann gesagt okay das ist zu teuer das zu lagern und zu warten weil mussten halt die batterien immer nachgeladen werden von denen weil diedie batteriebetriebenen sie die beatmungsgeräte waren halt auch noch batterie betrieben weil man nicht weiß ob im katastrophenfall man überhaupt strom hat und so.Alles alles super ja und der großteil des zeugs wurde halt dann irgendwie verramscht.Weiß nicht wo das abgeblieben ist also da gibt's noch vorher irgendwie jetzt ein paar reste von grade die sie versuchen zusammenzukratzen vonich weiß nicht wie viel beatmungsgeräte noch irgendwie ein drittel wohl steht wohl irgendwo rum und ja also wirklich ganz ganz traurig und leider nach der finanzkrise hatten durchaus auch leutedarauf gedrungen zu sagen ok finanzkrise ist jetzt vorbei können wir bitte das ganze wieder jetzt mal wieder aufbauenwieder in den zustand vor der finanzkrise aber es ist halt nicht erfolgt und da beißen sich jetzt glaube ich einige in den hintern und eigentlich müsste man da wirklich also der.Der damals das entschieden hat der demokratische gouverneurso der als dann die presse gefragt hat warum hast du das damals gemacht hat sich irgendwie geweigert sich dazu zu äußern.
Tim Pritlove 1:40:54
Techno responsibility.
Pavel Mayer 1:40:57
Ja gut das.
Tim Pritlove 1:40:59
Gerade in usa.Aber jetzt das alles was alles was du sagst dann da gehe ich auch voll mit andererseitsund das sind ja auch stimmen die man hört und die kann ich auch genauso gut nachvollziehen ist natürlich so dieses dogma.Klar man kann jetzt sozusagen unter dem gesichtspunkt von alles muss sicher sein ja oder maximal sicher sein kann man das natürlich jetzt alles so durch exerzieren und und und das sozusagen in den vordergrund stellen andererseits.Ist das nicht die einzige bedrohung die wir haben.Ja es ist man kann sich schnell ausrechnen dass wenn wir jetzt eine erhebliche erhöhte arbeitslosen situation haben sehr viele leute deren business was sie über jahre aufgebaut haben.Teilweise vielleicht unwiederbringlich zerstört ist nicht alles.Man kann sich in die komplexität einzelner wirtschaftlicher vorgänge nicht immer so ohne weiteres rein denken ja klar man denkt so naja macht er mal vier wochen pause geht schon wieder weiter.Es wird viele modelle geben die einfach nicht.Schon immer so an so einem ganz dünnen seil hängen und das sei es jetzt aber auch final gerissen ja da da werden insolvenzen und getriggert die vielleicht vorher gerade noch soebenzu verhindern gewesen wären aber jetzt ist er halt auch mit dem besten zuschaust nichts mehr zu machen zumal dann eben auch wie wir das jetzt schonangedeutet haben durch die geänderte wahrnehmung durch das geänderte verhalten etcetera diese modelle dann eben nicht tragen nicht mehr finanziert werden leute nicht mehr bereit sind in diesem bereich zu arbeiten sich nach was sicherem sehen etcetera p.Und das heißt wir werden dann eben auch durch ein tiefes tal durchgehen wo eben vieles von dem nicht mehr da istund was ich eben versucht irgendwie anders zu halten wenn man das jetzt eben gnadenlos weiter verschärft und sagt wir müssen jetzt alles verbieten und untersagen was in irgendeiner form zu gefährlichistja dann hat es eben auch keine möglichkeit eine eigene resilienz aufzubauen eine eigene methodik zu entwickeln vielleicht eben auch mit dieser ganzen virus krise umzugehen und dannist halt zu befürchten dass wir in so einem wirtschaftlichen abschwung landen und wer halt dann von so einer politischen situation.Profitiert kann man sich auch schnell ausrechnen ja das ist halt eine eine eine politische gefährdungdas eben so ein wirtschaftlicher niedergang schnell von leuten ausgenutzt wird die dann eben.Einfache lösung für komplexe fragestellungen haben und wir dann eben an der stelle eine verschärfung der situation sehen.
Pavel Mayer 1:43:46
Das kann natürlich kommen wobei man jetzt ganz gut gesehen hat eigentlich das sagen jetzt diedie populisten von denen du redest glücklicherweise zumindest in deutschland gerade nicht vielbeizutragen haben zu den lösungen wobei sie tatsächlich genau in diese kerbe beginnen halt hinein zu schlagen nach dem motto ist ja alles nicht so schlimm und eigentlich übertreibt und so.Und was uns das kostet und bis hin zu den usa so wo sich ja leute also wurde wo das sogar noch viel krasser ist die wo sich leute hingestellt haben gesagt haben.Ich will ich bin bereit lieber zu sterben als die zukunft meiner enkel irgendwie aufs spiel zu setzen hier alsowozu und es gibt irgendwie tausende von alten leuten die irgendwie genauso denken wie ich also ja wir sind bereit zu sterben der punkt istmein abgesehen davon ja gut auf den standpunkt kann man sich stellen was wo man aber natürlichnicht mit es geht ja nicht nur um diese person sondern um alle und es ist ja nicht so dass jeder für sich entscheiden kann irgendwie okay ich.
Tim Pritlove 1:45:10
Ich nehme ich mal raus aus der infektion.
Pavel Mayer 1:45:12
Ich nehme dich mal raus aus ich bin ich bin so genau ich mir ist es egal ich mache halt einfach nein dadurch gefährdet man ja auch andere und man kann ja darüber sodass es sagen der eine punkt der andere punktist warum sagen die maßnahmen jetzt auch absolut.Gerechtfertigt sind auch wenn sie so exorbitant viel kosten ist sagen die alternative die alternative ist nämlich und das sehen wir in den ländern ist dass das gesundheitssystem zusammenbricht undwenn das gesundheitssystem zusammenbricht führt es zum einen dazu dass ich sag mal fünf bis zehn mal so viele menschen sterbenist die sterblichkeit extrem viel höher ist aber das andere problem ist unser gesundheitssystem ist ja darauf ausgelegtauch irgendwie normale menschen die an anderen dingen erkrankt sind und es ist tatsächlich gerade die mehrzahl also im moment werden ich weiß nicht fünfundneunzig prozent der menschen die sich gerade in krankenhäusern befindenso oder vielleicht sogar achtundneunzig prozent sind da wegen was anderem was auch oft lebensbedrohlich istund wenn wir dann jetzt anfangen sagen wenn wir keine menschen mehr mit dir was anderes habenbehandeln können so dann reden wir nochmal von viel viel mehr indirekten totendurch durch corona wenn uns das außer kontrolle gerät und so bilder dann von irgendwie.Kühlwagen an krankenhäusern oder militärtransporter die halt dann ja sich um die leichen kümmern müssen und.
Tim Pritlove 1:46:58
Die will man auch nicht haben.
Pavel Mayer 1:46:59
Das willst will man einfach nicht haben das führt nämlich dann zu einer anderen art von zusammenbruch der ordnung insofern sind da jetzt wahrscheinlich einfach.Intelligentelösungen gefragt und dann auch solidarität gefragt ich kann mir vorstellen dass es auch noch um den wirtschaftlichen zusammenbruch zu vermeiden dass wir dass es sein könnte dass wir in so einer übergangs oder not wirtschaftdann hineinlaufen vielleicht auch mit dann rationierung vonbestimmten gütern die dann zentral verteilt oder zugeteilt werden wo ja wie das halt in früheren zeiten die wirlange oder die die meisten von uns nie erlebt haben aber so auch auch gegeben hat so dass das wär halt.Vorstellbar wenn es nicht gelingt.Sagen die wirtschaft rechtzeitig wieder ans laufen zu kriegen oder auf einem level auf dem laufenden zu kriegen das irgendwie alle leute wenigstens mit dem notwendigsten.Versorgen können und im moment scheint es ja noch ganz gut der fall zu sein also war jetzt zwar jetzt seit einer woche nicht mehr einkaufen.Oder so aber es scheint ja so zu sein was ich so gesehen habe die supermärkte sind gutbestückt und man das interessante wird sein dass möglicherweise waren die man gewohnt sind erstmal aus den regalen verschwinden weil sieaus dem ausland kommen und da erstmal gerade oder oder lieferketten haben insofern der intelligente hamsterradjetzt wahrscheinlich eher nach irgendwelchen luxusgütern die es dann zukünftig erstmal schwer zu haben kriegt gibt sobestimmte alkoholiker oder so.
Tim Pritlove 1:48:47
Der durchschnitt ist aber dann doch noch mehr hinter dem toilettenpapier und den mehl packung hinterher das kann ich dir bestätigen aus einem supermarkt besuch vor kurzem.
Pavel Mayer 1:49:00
Ja vielleicht noch einsatz sagen zum zum schluss sagen für die vorhersage jetzt für die nächsten ich sage mal für die nächsten vier wochen wie das wahrscheinlich so so aussieht weil damit solange etwas was wir zu erwarten habengesagt wir sollten eigentlich in zwei wochen spätestens sollte der zuwachs bei den infiziertenweitgehend gestoppt sein oder oder auf einem auf einem level sein wowir nicht mehr gefahr laufen dass durch die infizierten alleine die.Krankenhäuser sagen weiter beansprucht werden wobei es eben sich aber die sagen die belastung des gesundheitssystems etwas länger anhalten wird wenn wir es jetzt zum stoppen kriegen also dort ist der höhepunkt.Noch nicht erreicht so vermutlich dort eher in fünf bis zehn tagen unddas wird sich also noch im gesundheitssystem wird sich das noch nicht damit die nächsten vier bis sechs wochen wird dort noch verdammt viel los sein hoffentlich nicht die totale hölle.
Tim Pritlove 1:50:14
Wir könnten noch stunden weiterreden und wir werden wahrscheinlich auch noch ein paar stunden weiter reden aber nicht mehr in dieser sendung ich sage an dieser stelle vielen vielen dank.Ich hoffe dass die sendung auch schnell genug rausgedrückt bekomme auch bei mir gibt's richtig druck weg mittlerweile feststelle weil einfach es viele aspekte gibt die man so beleuchten kann und das habe ich hier auch noch vor das weiterhin zu tun denn.Aber sonst nicht so viel zu tun und von daher kann man sich auch mal wieder die welt kümmern und das haben wir jetzt getan also danke.Und das war's hier mein name ist tim danke pavel und dafür zuhören.
Shownotes


















 de.wikipedia.org SIR-Modell – Wikipedia
de.wikipedia.org SIR-Modell – Wikipedia
 Johns Hopkins Coronavirus Resource Center COVID-19 Map
Johns Hopkins Coronavirus Resource Center COVID-19 Map rocs.hu-berlin.de Forecasts by Country
rocs.hu-berlin.de Forecasts by Country GitHub Lewuathe/COVID19-SIR
GitHub Lewuathe/COVID19-SIR
Mein für daten.berlin.de zuständiger Kollege bringt ein Gutteil seiner Arbeitszeit damit zu, in der Verwaltung für strukturierte Daten und APIs zu werben. Es ist nicht leicht.
Unter https://npgeo-corona-npgeo-de.hub.arcgis.com/search?q=corona gibt es die Daten des RKI in Form einer API.
Vielen Dank, habe gestern per Twitter auch einen Hinweis auf Daten bekommen. Es kommt dem ziemlich nahe, was wir in der Sendung gewünscht hatten. Hatte vor einigen Wochen dort gesucht und damals nur das Kartenmaterial gefunden. Habe schon ein paar Ideen, was ich mit den Daten machen werde.
Gute Sendung mit Aspekten die bis jetzt nicht so an die Öffentlichkeit dringen.
Mehr Disclaimer wären notwendig gewesen.
Pavel ist ein sehr vernunftbegabter Mensch und pflegt im Allgemeinen offenbar die richtige Einschätzung zu Datenqualität und Schwierigkeiten von Inferenz aufgrund von Modellen, aber dass er hier Prognosen aufgrund eines sehr problematischen Modells verkündet hat, war sehr bedenklich. Ich finde es schwierig, dass wieder gefährliches Halbwissen verbreitet wurde, während gleichzeitig der Anschein gewisser wissenschaftlicher Kompetenz erweckt wurde.
Nach der Beschreibung seines model fitting-Prozesses, erscheint es mir, dass Pavel hier wirklich unbedarft und nicht vertraut mit den notwendigen Techniken an die Sache herangegangen ist. Probleme die er als schwierig angehbar beschreibt, haben jedenfalls in meiner Disziplin, der ökologischen Modellierung, bekannte Antworten, und andere Problemlösungen erscheinen mir schlicht falsch (mein Disclaimer: Bin auch kein Epidemiologe, kein epidemiologischer Modellierer, nur gewöhnlicher Naturwissenschaftler).
1. Zum SIR-Modell: Es hört sich so an als würde Pavel da ein sehr vereinfachtes Prozess- oder state-space-basierte Modell mit einem einfachen least-squares-Optimierer fitten. Es ist kaum verwunderlich, dass der Fit nicht plausibel war. Die offensichtlichen und bekannten Strategien wären hier: Einführung von Stochastizität im Prozessmodell, vor allem Einführung eines stochastischen Beobachtungsmodells mit verschiedener Parametrisierung für verschiedene Länder etc., und evtl. bayes’sche Kalibrierung mit prior probability distribution auf den Parametern, so dass diese in gewissem Rahmen „regularisiert“ werden.
2. Zum logistischen Modell: Natürlich kann man immer ein naives logistisches Modell fitten, aber die Erklärungskraft der Parameter ist eher gering, weil wir wissen, dass wir es nicht mit einem logistischen Prozess zu tun haben (sonst müsste das Wachstum an seine eigene Limitierung gekoppelt sein; wir wissen aber dass unsere Eindämmungsmaßnahmen 1. unabhäbhig vom Wachstum und 2. nicht etwa an irgendeiner Sättigungsgrenze absolut wirksam sind)! Auf der gefitteten Kurve Analytik zu betreiben und von Wendepunkten zu sprechen ist nicht richtig und ohne Disclaimer nahezu unverantwortlich. Auch die Konfidenzintervalle des SIR-X-Forecastings aufgrund ihrer großen Unsicherheit als „unbefriedigend“ zu bezeichnen, und dann Boundaries für Forecasts aufgrund von Standardabweichungen vorzuschlagen ist wirklich ein problematisches und m. E. unbegründetes Verfahren. Gute Wissenschaftler würden sich extrem davor hüten Forecasts aufgrund dieser Methode zu machen. Die Modellgüte besteht nicht allein aus der prädiktiven Kraft, sondern auch der Fähigkeit Prozesse zu erklären, und der richtigen Einschätzung der Unsicherheit. Vor allem letzteres wurde hier vernachlässigt.
5. Das Wichtigste: Es reicht nie, einfach mathematische Modelle anzuwenden, sondern man braucht spezifisches Fachwissen, um die Daten aufbereiten zu können, Prozesswissen um Sonderfälle zu erkennen und Plausibilität zu beurteilen. Es ist eine allgemein verbreitete Krankheit, dass mathematikversierte Menschen, sich auf eine Disziplin stürzen und Modelle falsch anwenden.
Ich bin mir sicher, eine Expertin zur epidemiologischen Modellierung, der ich nicht bin, hätte zu dem Thema noch mehr zu sagen. Es wäre wirklich hilfreicher eher „Profis“ zu diesem Thema anzuhören.
Da ist es auch eher kontraproduktiv, am Beginn der Sendung Pavels Autorität aufzuplustern, indem man auf seine Abgeordnetentätigkeit oder Erfahrung mit quantitativen Wissenschaften hinweist. Man hätte ganz im Gegenteil mehr betonen sollen, dass Pavel vom Thema epidemiologischer Modellierung keinen blassen Schimmer hat und hier nur dilettiert. Diese Einordnung wäre wirklich angemessen gewesen.
Danke. Ich finde diese klassische Nerdeigenschaft, zu glauben man könne Aussagen über diverse komplexe Sachverhalte machen, weil man bestimmte komplexe Sachverhalte versteht, wirklich unangenehm. Gerade in der aktuellen Situation, in der wir als Gesellschaft(en) darauf angewiesen sind, dass alle so gut wie möglich verstehen, was passiert, damit sie ihr Verhalten anpassen können, schadet es mE eher, die Unübersichtlichkeiten der Realität noch mit dem eigenen Halbwissen zu verstärken.
Ich wundere mich sehr, dass Pavel und Tim (deren öffentliche Äußerungen ich für gewöhnlich sehr schätze) an dieser Stelle weiter machen, obwohl es doch mehr als genug kritische Hinweise gab. Reflektiert ihr das?
Ich gebe dir Recht, dass Alle möglichst gut verstehen sollten, was los ist, und was dieser Podcast auf jeden Fall ist, ist eine Dokumentation des Zeitgeschehen, wie gerade zwei Leute versuchen, sich einen Reim auf das Geschehen zu machen und andere daran teilhaben lassen.
Zwei Leute, die mit Verlaub eine Menge gesehen und gemacht haben und bei allem Nerdtum sich nicht darauf reduzieren lassen,
„Halbwissen“ halte ich gerade auch für einen etwas polemischen Begriff, als ob es gerade jemanden mit Vollwissen gäbe. Ich denke, wir haben an den meisten kritischen Stellen hinreichend dazugesagt, wo gerade die Grenzen unseres Wissens liegen.
Es tut sich gerade auch soi viel, und ich trage Wissen aus ausschliesslich renomierten Quellen zusammen und nehme mir einige Zeit dafür, weise in der Regel auf die Quellen hin und stelle meine Ergebnisse nicht über die der Profis, versuche aber ihre Arbeiten nachzuvollziehen, so weit es mit möglich ist.
Ich bin offen über das, was ich mache und gebe meine Einschätzung der Situation wieder, und es kann natürlich Zufall sein, aber fast Alles von dem, was ich seit Wochen dazu auf Twitter geschrieben habe, trat so ähnlich ein oder wurde manchmal erst Tage später z.B. von Christian Drosden verbreitet bzw. bestätigt, etwa die Zahlen zu durchgeführten Tests.
Ich bin sehr gespannt, wie dieser Podcast so altern wird. Es ist immer gefährlicher, Vorhersagen zu machen als sich bedeckt zu halten, und es wird im Nachhinein sicher interessant sein zu sehen, wie ahnungslos wir vielleicht auf die Zukunft zugesteuert sind oder auch nicht, uns ich denke, zumindest mein WIssen über die Bedeutung und das Zustandekommen der öffentlichen Zahlen deckst sich mit praktisch allen Expertenaussagen, und da, wo sie sich wiedersprechen, weiss ich in der Regel, wer die aktuelleren oder zutreffenderen Informationen hat, und dieses Wissen halte ich für Wert, geteilt zu werden.
Im Übrigen gab es neben den „kritischen“ Hinweisen nach dem letzten Podcast zum Thema sogar zum einen deutlich mehr Zuspruch als negative Kritik, zum anderen sind wir der Kritik nachgegangen und haben uns einige Passagen mehrfach angehört und konnten nicht erkennen, dass die Kritik in Substanz oder Inhalt zuftreffend war; entweder hatten wir gar nicht gesagt, was uns vorgehalten wurde, oder was wir gesagt hatten war zutreffend und wurde von uns mit Belegen versehen.
Insofern ist Kritik meist nur dann hilfreich oder hat Konsequenzen, wenn sie auf möglichst konkrete Punkte abziehlt, an denen wir noch mal gezielter in die Tiefe prüfen können, ggf. Quellen hinzufügen oder Berichtigungen oder Klarstellungen machen können.
Hinweise wie „Nerds“ und „Halbwissen“ helfen uns leider nicht, den nächsten Podcast zum Thema irgendwie besser zu machen, wobei wir uns natürlich gtundsätzlich über jeden Kommentar erst mal freuen.
Ausserdem dürfte das hier kaum die einzige Quelle von Informationen sein, die jemand gerade zum Thema bezieht, und wir haben hier auch hinreichend Verweise auf viele unsere Quellen, wo sich jeder noch mal selbst versichern kann, ob wir das richtig wiedergegeben haben. Bisher ist mir ein solcher Fall nicht bedankt.
Eine andere Sache sind natürlich unsere Einschätzungen und Meinungen zu dem Thema, wozu auch gehört, wem wir glauben, und natürlich auch wie wir glauben, dass es weitergehen könnte. Auch die Wissenschaft kann gerade nur verschiedene Szenarien aufmalen, von den wir einige unbedingt vermeiden müssen. Insbesondere können wir sehen, was überhaupt noch möglich ist.
Falls du konkrete Kritikpunkte hast, würde ich gerne davon hären; wir werden nämlich wohl am Thema dranbleiben, und innerhalb einer Woche kann sich gerade verdammt viel tun, und das Thema wird uns vielleicht noch Jahre beschäftigen 🙂
Hey Pavel,
danke für die Reflektion. Wir beide schätzen die Lage wohl prinzipiell aus ganz unterschiedlichen Perspektiven ein, ich will nochmal versuchen, das besser darzulegen.
Ich habe an der Uni Statistik 1 und 2 gehört, beherrsche R halbwegs und Python ganz gut, habe zumindest Ansätze für Optimierung und Erfahrung mit großen Datenmengen und machine learning. Es könnte mir vielleicht auch passieren, dass ich Lust bekomme, mich mit den Covid-Daten hinzusetzen und mal zu schauen, wie weit mein Skillset reicht und ob ich zu interessanten Analysen oder Interpretationen komme. Soweit glaube ich gut zu verstehen, was Du machst. Und an dieser Stelle sei gesagt, dass Du mir inhaltlich ganz sicher um Längen voraus bist und ich nicht an Deinen Fähigkeiten und Deiner Vorsicht bei Aussagen zweifle. Mir käme allerdings niemals der Gedanke, zu so einem Projekt in so einer unübersichtlichen Gesamtlage dann podcasts rauszuhauen.
Aus zwei mir wesentlichen Gründen: 1. Dunning Kruger. Es muss Lücken in meinem Wissen und in meinen Fähigkeiten geben und je weniger tief ich in einem Fachgebiet stecke, desto weniger kann ich über die Größe und Beschaffenheit dieser Lücken sagen. Ich unterstelle (quasi heuristisch), dass das bei Dir auch der Fall ist. Das habe ich (ja, verkürzt und polemisch, auch ich mache gerade coping und bin gestresst) als Halbwissen bezeichnet. Ich bitte Dich dafür hiermit um Entschuldigung und hoffe, dass ich etwas differenzierter erklären konnte, worauf ich hinaus wollte.
2. Funktion in gesellschaftlichen Debatten: UKW dürfte recht große Teile unserer community erreichen, was ihr sagt hat also Einfluss. Im Diskurs bildet ihr eine meines Erachtens ungute Brücke zwischen der großen Gruppe derer, die gerade sehr interessiert daran sind, die wissenschaftlichen Perspektiven auf die Pandemie zu verstehen (deshalb hat Drosten mit dem Coronavirus Update so erstaunlich viel Zulauf) einerseits und der Gruppe, die findet, dass kritische Begleitung der Krise bedeutet, Videos von (mal wieder) Lungenfachärzten zu verbreiten, andererseits. Achtung, ich argumentiere gerade nicht, dass Dein Kenntnisstand und Deine Sorgfalt mit Wodarg in einen Topf gehören. Das tun sie nicht. Aber die Konstruktion: Ich bin interessierter Enthusiast und habe hier einige themenverwandte Qualifikationen und Erfahrungen aufzuweisen und deswegen nehme ich jetzt am Diskurs zur Pandemiemodellierung teil; ähnelt strukturell schon auch der Konstruktion, die jetzt vielfach an den Rändern der Debatte aufgemacht wird. Damit besteht aus meiner Sicht das Risiko, dass Menschen die Einschätzung der Quellenlage misslingt (Pavel ok, Wodarg nicht) und ihr unbeabsichtigt einen Beitrag zur Diskursverschiebung leistet.
Nochmal abschließend: Du hast mich gebeten, Dir inhaltliche Fehler nachzuweisen. Das kann und möchte ich nicht, weil meine Copingstrategie eine andere ist als Deine (mir täte es nicht gut, jetzt zu versuchen, mich soweit in die Modellierung einzuarbeiten, dass ich Dir inhaltlich sinnvoll widersprechen könnte und ich bin wirklich gerne bereit, Deinen Wissensvorsprung anzuerkennen und mit Klappe halten zu würdigen). Stattdessen habe ich versucht, darzulegen, dass es auch Gegenargumente auf einer anderen Ebene geben könnte. Ich bin ok damit, wenn Du die ablehnst, mir ist es trotzdem wichtig, dass wir auch solche Perspektiven diskutieren.
Vorab auch erst mal: Ich bin dankbar für deinen Kommentar und deine Anregungen und höre gern mehr davon. Teilweise finde ich deine Kritik allerdings zu harsch und möchte sie nicht unerwiedert stehen lassen. Ich möchte das jetzt nicht in einen Rechthaberei-Thread ausarten lassen und denke, dass du dich mit Modellierung auf einem verwandten Gebiet besser auskennst als ich. Die Frage ist: Inwieweit hast du dich mit den Corona-Daten beschäftigt?
Ich denke, ich habe mehrfach betont, kein Epidemiole zu sein und keine Experte auf diesem Gebiet. Denoch glaube ich, etwas Wertvolles beizutragen und bemühe mich, keine Fehlinformationen zu verbreiten. Ich verbringe auch sehr viel Zeit damit, Informationen zusammenzutragen, und ich denke, dass selbst, wenn ich an manchen Stellen Unzuftreffendes gesagt haben sollte, sollte das diesen Podcast nicht derart entwerten, wie es für dich den Anschein hat.
Zum einen liefert er denke ich hinreichend viele Verweise auf andere, insbesondere die offiziellen Akteure, deren Arbeit ich vorangestellt und wie ich denke auch nicht niedergemacht habe, sondern im Gegegnteil herausgehoben habe, dass wir hier im Vergleich zu den ROCS-Hauptarbeiten bei den hier diskutierten Vorhersagesystem von einem sehr einfachen Modell reden, was auf der Seite im Übrigen eingehend beschrieben ist und an dem ich mich orientiert habe. Wäre alles einfacher zu beurteilen, wenn sie auch noch einen Link zu einem git-Repository vom Quellcode angeben hätten. Oder Daten. Oder alle Parameter.
Bitte bedenke auch, dass es bei dieser Situation mit Expertentum allein nicht getan ist; iregendwo müssen Dinge auch integriert und politisch bewertet werden, und ich kenne (wie du vermutlich noch mehr) genug Experten, um zu wissen, dass die meisten auch eine Agenda und eine persönliche Meinung haben, und nicht alle sind in einem so hohen Maße auf eine Trennung von Wissenschaft und Politik bedacht wie Christian Drosten, und ich bin froh dass ihm diese führende Rolle in der wissenschaftlichen Beratung der Regierung zugefallen ist. Ich könnte mir kaum jemand besseren ausdenken.
Dennoch ist es nötig, mäglichst viele Informationen und Daten und Modelle und Ergebnisse einer breiten Öffentlichkeit zugänglich zu machen, damit nicht nur ausgewählte Experten Einblick haben, sondern breiter nachvollziehbar ist, was gerade geschieht. Worauf basierten die Entscheidungen des Bundes und der Länder? Ich verstehe, dass es Mühe und Arbeit macht, auch Quellen und Urdaten mit bereitzustellen, aber eigentlich sollte das auch bei uns mittlerweile zum guten wissenschaftlichen Ton gehören, tut es in vielen Bereichen aber noch immer nicht.
Wenn ich hier rumdilletieren sollte, ist das eher Ausdruck dieses Problems und als Aufforderung und Ruf nach mehr Transparenz zu verstehen, denn sonst laufen wir Gefahr, unnötig Widerstand zu erzeugen, je länger die Maßnahmen andauern.
Zu 2., zur Erklärungskraft der Parameter im logistischen Model und dem Modell allgemein: Ich denke, auf die Limitationen des Modells und der beschränkten Aussagekraft hinreichend hingewiesen zu haben. Hätte ich alles mit einem Disclaimer versehen müssen, hätte die Sendung doppelt so lange gedauert.
Was das Modell tut, und zwar in mehreren Ländern, Vorhersagen zu treffen, die sich mit dem SIR-X weitgehend decken die nächsten 3-5 Tage ziemlich treffsicher vorraussagen. Für die Zeit danach kann man denoch Szenarien damit entwerfen, und die Analytik auf der logistischen Kurve ist gut genug, um zu erkennen, ob ein Trend zu erkennen ist und in welcher Phase sich die Epidemie befindet. Und dass man Best-Case Szenarien gut entwerfen und den Worst-Case eher schlecht. Ich bin mir der Grenzen logistischer Kurven sehr bewusst, aber wenn sie nicht bisher so gut funktionieren würden, auf realen Daten, hätte ich mich nicht so viel damit beschäftigt. Und zu den Parametern: Sie ermöglichen unter anderem einen guten und schnellen Ländervergleich und haben auch gute und direkte Interpretationen.
Ich würde mir wünschen, du würdest dir die Sendung noch mal objektiv daraufhin anhören, ob das von mir hier gesagte zutrifft und villeicht in Gedanken eine Strichliste anfertigen, an welcher Stelle du nütztliche, richtige, irrelevante oder falsche Informationen siehst. Ausserdem wäre ich für weitere sachdienliche Hinweise und Quellen sehr dankbar, wie Viele, die das hier lesen.
Am besten wäre es natürlich, wenn deine spürbare Verärgerung oder Enttäuschung dazu führen würde, dass jemand mit deiner Expertise sich über das Problem hermacht und uns daran teilhaben lässt.
Mir hat es alles jedenfalls sehr geholfen, ein Gefühl für die zeitlichen Abläufe und Dynamiken zu gewinnen und Schlüsse zu ziehen, die überwiegend bestätigen, was die Regierung so sagt und was sie in der Tat nicht wissen kann. Fand ich sehr beruhigend.
Hallo Pavel,
ich finde es sehr gut, dass du dich mit der Modellierung beschäftigst und deine Ergebnisse mit der Öffentlichkeit teilst. Was mich am Podcast gestört hat, ist dass es sich – gerade nach der erhebenden Vorstellung von Tim – für Unbedarfte so angehört haben muss, als würdest du quasi die überlegenen Modelle produzieren. Was du machst ist cooles Hacking (ein schöneres Wort für Dilettieren) und Spielen, aber so hätte man es eben mehr einordnen, und die Vorhersagen mit mehr Salz versehen sollen, finde ich. Trotzdem weitermachen, davon sollten dich meine harschen Worte bitte nicht abhalten 🙂
Ich glaube übrigens gern, dass die logistischen Kurven gerade gut predicten, aber ich glaube auch, dass diese prädiktive Kraft sehr schnell nachlassen wird, sobald sich das limitierte (sub-)exponentielles Wachstum in den Daten noch etwas fortsetzt.
Ich hätte gedacht, allein die hohen Fehlerraten wären Salz genug gewese, zusammen mit den die vielen genannten Einschränkungen. Muss mir aber wohl vorwerfen lassen, in meiner Freude darüber, wie gut es funktioniert und wie einfach handhabbar die logistischen Kurven im Vergleich zu SIR sind, wenn es um schlechte Daten geht, und die Fits sind geradezu unheimlich gut, was ich erst mal nicht glauben konnte.
Du hast auch absolut Recht, was das limitierte (sub-)exponentielle Wachstum angeht. Was der Fit dann dann aber wie aktuell im Fall China zeigt ist, dass eben genau diese Phase erreicht ist und das tatsächliche Wachstum von der logistischen Kurve abweicht. Diese eignet sich also sehr gut als Referenz um zu sehen, was passieren müsste, um zum Stillstand zu kommen.
Ein anderer von mir nicht erwähnter Aspekt ist, dass ich die logistische Kurve auch auf beliebige Abschnitte der Kurve legen kann, und wenn ich erkenne, dass z.B. bestimmte frühere Werte nicht mehr relevant sind, kann ich den Fit entsprechend anpassen.
Der Punkt, den ich nur machen wollte ist, dass das SIR-X Verfahren für grobe Erkenntniszwecke aus einer verrauschten, kleinen Datenbasis eigentlich auch keine besseren Ergebnisse liefert als Curve-Fitting, letzteres aber leichter nachvollziehbar und handhabbar ist und überraschend gut funktioniert, besser, als ich es anfangs für möglich gehalten hätte.
Ich habe damit auch nicht den Stein der Weisen gefunden, Richard’s Curve https://en.wikipedia.org/wiki/Generalised_logistic_function ist von 1959, und hat es nicht mal in die deutsche WIkipedia geschafft, insofern weiss ich nicht, ob du dich bei deiner Kritik auf die „normale“ Logistikfunktion bezogen hast, die weniger Paramter hat. Dennoch hast du Recht, jede vereinfachte Funktion passt iregendwann nicht auf den realen Verlauf, aber dasselbe gilt für die SIR-Modelle, wenn man nicht „unterwegs“ von Hand die Parameter ändert. So richtig vorzusehen scheinen mir die Modelle das allle nicht, dass sich in kurzer Zeit ein Parameter ändert, obwohl man das natürlich programmieren kann, aber für jeden Wechsel führe ich dann faktisch neue Parameter ein bzw. diskrete Werte, und das finde ich ziemlich umständlich, aber vieleicht fehlen mir auch die Tools und Kenntnisse und die Zeit, das so tief reinzugehen.
Ich vermute, es wird alles besser, wenn man die geografische Dimension mit einbezieht, aber das schafft natürlich Komplexitäten und neue Fehlerquellen, und manchmal ist eine schnelle, nachvollziehbare, nicht so genaue Antwort auch besser als eine, die ich erst Wochen später erhalte, weil ich erst mal die Probleme in meinem Modell ausbügeln musste. Was ich so gesehen habe, auf das die Bundesregierung ihre Entscheidung gestützt haben soll, war jetzt nicht so sophisticated, aber vermutlich schon zu kompliziert für die meisten Politiker, würde ich sagen.
Ich denke, ich überbewerte das Curve-Fitting nicht, aber man sollte es vielleicht auch nicht unterbewerten – die richtige Funktion für den richtigen Zeitraum vorausgesetzt. Und wie gesagt, es ist geradezu unheimlich, wie gut Richard’s Curve passt, besser und auf mehr, als ich es für möglich gehalten hätte, aber eben auch nicht naiv auf Alles.
Leider waren beide Podcasts sehr unangehem zu hören.
Wie die Kommentatoren über mir schon gesagt haben würde etwas Demut vor der Komplexität des Themas gut tun. Der Drosten sag täglich 10x das er sich selbst bei Themen die sein Fachgebiet tangieren nicht sicher genug fühlt gewisse aussagen zu tätigen oder Sachverhalte zu kommentieren. Hier kommt es einfach sehr arrogant rüber und statt der in der Einleitung erhofften Einsicht wurde Pavel einfach zum Universalexperten erklärt…
Vielleicht liegt es am Thema aber ich habe mich noch nie so unwohl oder eher verärgert beim Hören eines Metaebene Podcasts gefühlt (und ich habe wirkliche alle gehört)
Moin.
Auch ich komme aus der Ecke der Modellierer (Geoökologie) und habe einst an (räumlichen) Ausbreitungsmodellen herumgeschraubt. U.a. auch mithilfe der Richards-Kurve.
Und ja, mit bestimmten Anpassungen x-beliebiger Parameter kriegt man viele Daten gefittet und es sieht erst einmal plausibel aus. Da freut sich jeder Modellierer für drei Minuten.
Doch braucht es dann doch spezifisches (Fach)Wissen, um eigenartiges Verhalten und numerische Artefakte erkennen zu können. Da fallen die Modelle nämlich auch schnell mal auseinander oder werden hinten raus chaotisch.
Die Wahl der Anfangs- und Randbedingungen machen das Geschäft auch nicht einfach und gerade speziell die Datenlage bei der Corona-Krise ist doch ein Alptraum für jede/n, die/der Anfangsbedingungen klar definieren möchte.
Bromions Einwände unterstütze ich alle.
Die Tücken der (numerischen) Modellierung lernt man erst nach Jahren mehr und mehr kennen. Und auch ich hatte den Eindruck (nur den Eindruck!), dass Pavel sich einmal kurz da eingelesen und dann schnell losgelegt hat.
Das soll Dich, Pavel, nicht von Deiner Neugier abhalten. Neugier ist immer schön und gut. Aber wenn viele Zuhörer:innen eben diesen Eindruck haben, dann einfach noch etwas besser kommunizieren?
Sonst bitte weiter so weitermachen!
Disclaimer: Ich habe exakt 0.0 Domänenwissen bzgl. Epidemiologie und fitte alle Jubeljahre mal ’ne Kurve, um flotte Approximatoren für gesamplete Daten zu bauen. Es kann also sein, dass meine Frage kompletter Dünnpfiff ist. Intuitiv fand ich Bromions ersten Einwand unter 2. („kein logistischer Prozess“) aber recht plausibel, deshalb nur mal so aus Neugier:
Hattest Du bei Deiner Analyse auch mal nach höher parametrisierten logistischen Modellen (sprich: 5PL o.Ä.) oder „exotischeren“ Sigmoiden gestöbert, für deren Parameter es vielleicht noch plausiblere bzw. kleinteiligere domänenspezifische Interpretationen gibt? Ich weiß natürlich nicht, wie tief Du Dich in die Epidemiologie i.e.S. reingenerdet hast, aber ich könnte mir vorstellen, dass (falls sowas existiert) die Grenzen des Modells damit noch etwas klarer zu Tage träten – selbst wenn ’ne Standard-Richards-Kurve schon perfekt passt.
P.S. Das ist natürlich nicht als Fangfrage gemeint (bei 99% der anderen Takes, würde ich mir wünschen, dass sie so tief eintauchten wie Du). Ich frage mich nur gerade, wieviel Erkenntnisgewinn man sich grob davon versprechen darf, nochmal ’nen Domänenexperten darüber zu befragen.
Dunning-Kruger hat zugeschlagen. Ich kann Parameter eingeben in eine Funktion eingeben und habe mal „für ein Krankenhaus gearbeitet“. Deswegen kann ich natürlich bessere Modelle entwickeln als Menschen, die in diesem Bereich forschen. Teile der Sendung waren kurz vor „Ich bin Ingenieur und Stahl kann bei diesen Temperaturen nicht schmelzen“
Hast du konkrete Kritikpunkte, oder wolltest du einfach mal pauschal Unmut oder Unzufriedenheit mit dem Podcast äussern?
Sollte letzteres der Fall sein, tut es mit leid, dass du nicht genug Positives daraus ziehen konntest.
Solltest du konkrete Kritikpunkte haben, würde es mich freuen, die zu erfahren.
Danke euch auch für die zweite Folge. Mir gefallen eure Momentaufnahmen sehr.
Werfe mich mal ins Feuer und behaupte, dass im Gesagten gut rüber kommt, dass eure Gedanken und Pavels Analysen auf diversen Annahmen basieren.
Eure Erläuterungen helfen, den Wust an Zahlen & Infos etwas besser einzuordnen. In wieweit man eure Vorhersagen für bare Münze nimmt bleibt ja jedem selbst überlassen…
Ihr habt die Maßnahmen nur kurz angeschnitten, ich möchte mir trotzdem eine Ergänzung erlauben. Trotz bundesweitem Abstimmungsversuch sind die Maßnahmen auf der rechtlichen Ebene der Verfügungen und Verordnungen im Detail deutlich unterschiedlich – nicht nur in Bayern. Dort braucht es einen „trifftigen Gründen“ die Wohnung zu verlassen. Man darf sich in unter freiem Himmel auch zu zweit mit niemanden Treffen außer dem festen Partner oder Menschen der eigenen Wohnung. Auch Treffen in der Privatwohnung sind untersagt.
Auf der anderen Seite der rechtlichen Maßnahmen stehen Bundesländer die Terffen von zwei Personen in der Öffentlicheit nicht verbieten, Treffen in Privatwohnungen nicht verbieten und generell keine „trifftige Gründe“ für das Verlassen der Privatwohnungen kennen. Dazu kommen deutliche Unterschiede bei den Bußgeldern und in der Rechtsdurchsetzung. Abseits von den medizinischen Empfehlungen halte ich die rechtlichen Maßnahmen in einigen Bundesländer für unverhältnismäßig in anderen angemeseen abgewogen, wenn sie zeitlich strikt begrenzt werden. Ich würde deshalb auf rechtlicher Ebene zugespitzt sagen „die Maßnahmen“ gibt es nicht.
@min 56 etwa: Impfschäden . Insbesondere in Anbetracht dessen, dass es bei der letzten ( oder war s schon vorletzte ? ) Epidemie, der Schweinegrippe, wenn ich mich recht entsinne, arge Probleme mit den Impfungen gab. schwere NW, die auch ( nachträglich ) pharmakologisch erklärbar durch den Impfstoff getriggert wurde : Narkolepsie -> https://www.aerzteblatt.de/nachrichten/63356/Grippeimpfung-Wie-Pandemrix-eine-Narkolepsie-ausloest
Ich fand Pavel gar nicht arrogant. Ich kenne ihn nicht und fand die Hinweise auf seine eingeschränkte Kompetenz zu Beginn ausreichend.
Das starke Auseinanderklaffen von Minimal- und Maximalwertschätzung für 5 Tage unterstreicht, neben der Anmerkung, dass es für längere Zeiträume dann ganz unbrauchbar wird, den experimentellen Charakter der Berechnungen hinreichend unterstreichend.
Ich bin ja noch ein viel größerer Dilettant auf dem Gebiet und versuche aus den Zahlen von gestern und heute auch ständig zu orakeln, was morgen sein wird. Indem ich Dritten dabei zuhöre kann ich, wenn ich „Dunning Kruger“ rufen will, lernen, mir an die eigene Nase zu fassen.
Außerdem entnehme ich dem Halbwissen hier und dem Halbwissen andernorts immer wieder Informationsatome, die ich selbst übersehen habe und höre Fragen, auf die ich selbst nicht gekommen bin.
Besser als unreifes Zeug nur im eigenen Kopf zu wälzen, ist es, sich mit anderen darüber auszutauschen, die zumindest theoretisch in der Lage sind die Schwächen in den Überlegungen aufzudecken. Ein defensives Irrtum-vermeiden-um-jeden-Preis scheint mir die schlechtere Strategie zu sein.
Hätten wir geschwiegen, wären wir alle Philosophen geblieben, ja, aber nicht jeder will auf einem Marmorsockel enden. 🙂
Und was man sich selbst als Kritikfähigkeit zuschreibt, sollte man vielleicht auch nicht allen anderen absprechen.
In den letzten Tagen kam die Debatte um die Grundrechte und das staatliche Eingreifen auf; ich schätze es sind konkrete Pläne der Regierung den aktuellen Ausnahme-Zustand auf Jahre auszudehnen an die Presse durchgesickert. Telefondaten sind da nur ein kleines Mosaikteilchen, es geht direkt ums große Ganze:
Es wird sicherlich zu verhandeln sein, inwieweit die Bevölkerung bereit ist so ziemlich alle ihre Grundrechte zu opfern um die eigene Überlebenschance ein wenig zu verbessern bzw anderen Menschen das Überleben zu ermöglichen.
Und dann ist die Frage, ob die Bevölkerung das überhaupt entscheiden kann, es gibt ja keine Volksentscheide übers Grundgesetz.
Da werden wohl die Juristen ran müssen und das wird jedenfalls spannend: Staat will GG aushebeln, Juristen könnten das verhindern.
Wo will man sich da positionieren?
Ich finde jedenfalls, das kann man nicht einfach in drei Sätzen abbügeln von wegen das seien ein paar Rentner die bereits sind zu sterben könnten sich ja nicht der Welt entziehen. Spaßfakt: können sie wohl.
Machen diverse Religionsgruppen auch. Oder einzelne Staaten.
Man muss die Welt oder Deutschland nicht als große Monokultur begreifen, und die Problematiken von Monokulturen (Anfälligkeit für Schädlinge und Krankheiten) als gottgegeben hinnehmen. Monokulturen sind äußerst produktiv, das stellt niemand in Abrede. Aber sie sind nicht der Weisheit letzter Schluss.
Man könnte den Menschen die Wahl lassen, wo und wie sie leben wollen und ihnen mehrere Modelle anbieten: Quarantäne-Deutschland hier, Anti-Quarantäne-Deutschland dort.
Wenn es um dermaßen viele Menschen geht, gibt es keine „richtige“ Lösung für alle. Es gibt wahrscheinlich nicht mal eine „richtige“ Lösung für die Mehrheit, sondern nur das kleinste Übel für eine große Minderheit.
Aber dann wird es schwierig mit der Legitimität und die Frage ist, ob man im Namen einer Ideologie „no borders, one system“ nicht alles andere opfert was das Leben lebenswert macht.
Ich unterstütze die Kritik und die Anmerkungen von Bromion.
Bedauerlich finde ich den Umstand, dass die laufenden Zahlen der wegen Covid-19 hospitalisierten Patienten, und die Zahlen derer, die aktuell intensiv behandelt werden ebenso wenig veröffentlichet werden, wie die Zahl der freien Intensivbetten. Denn das sind ja gerade die wesentlichen Parameter, um einen akzeptablen Kompromiss zwischen „flatten the curve“ und den die Infektionszahl reduzierenden Maßnahmen zu finden. Der aus gesundheitlicher Sicht optimale Zustand, in Stase abzuwarten, bis ein Impfstoff oder ein wirksames Medikament ausreichend zur Verfügung steht, ist gesellschaftlich und wirtschaftlich nach den bisherigen Schätzungen nicht durchhaltbar.
Zudem gebietet es die Ethik, die restriktiven Maßnahmen nur soweit zu reduzieren, dass Triage-Entscheidungen aufgrund von fehlenden Kapazitäten bei der med. Behandlung nicht notwendig werden.
Aufgrund der Zahl der bereits Infizierten aus dem med. Bereich vermute ich, dass es dort noch erheblichen Nachholbedarf beim Infektionsschutz und im Umgang mit der Schutzausrüstung gibt.
Zu den Grundrechten möchte ich noch anmerken, dass es überhaupt keine Rechtsgrundlage dafür gibt, die Rechte bereits immuner Personen weiter einzuschränken.
Die Zahlen werden durchaus veröffentlicht. Regelmäßig in den täglichen Situationsberichten des Robert-Koch-Instituts, beispielsweise dem heutigen: https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Situationsberichte/2020-04-08-de.pdf (Seite 5 und 6). Und natürlich im DIVI-Intensivregister (ist im PDF verlinkt).